

Carry this mission to life
On this article we introduce Actual-Time DEtection TRansformer (RT-DETR), the primary real-time end-to-end object detector addressing the difficulty of the excessive computational price current with the DETRs. The current analysis paper DETRs Beat YOLOs on Actual-Time Object Detection, a Baidu Inc., efficiently analyzed the damaging impression of non-maximum suppression (NMS) on real-time detectors and proposed an environment friendly hybrid encoder for multi-scale characteristic processing. The IoU-aware question choice enhances efficiency. RT-DETR-L achieves 53.0% AP on COCO val2017 at 114 FPS, outperforming YOLO detectors. RT-DETR-X achieves 54.8% AP at 74 FPS, surpassing YOLO in each pace and accuracy. RT-DETR-R50 achieves 53.1% AP at 108 FPS, outperforming DINO-DeformableDETR-R50 by 2.2% AP in accuracy and 21 instances in FPS.
Object detection is a process of figuring out or localizing sure objects in a picture or video. Object detection fashions have numerous sensible purposes throughout completely different domains akin to:
- Autonomous Automobiles: Object detection is essential for enabling autonomous automobiles to determine and monitor pedestrians, automobiles, site visitors indicators, and different objects on the highway.
- Retail Analytics: In retail, object detection helps monitor and analyze buyer habits, monitor stock ranges, and scale back theft by the identification of suspicious actions.
- Facial Recognition: Object detection is a elementary part of facial recognition methods, utilized in purposes akin to entry management, identification verification, and safety.
- Environmental Monitoring: Object detection fashions will be utilized in environmental monitoring to trace and analyze wildlife actions, monitor deforestation, or assess modifications in ecosystems.
- Gesture Recognition: Object detection is used to interpret and acknowledge human gestures, facilitating interplay with units by gestures in purposes like gaming or digital actuality.
- Agriculture: Object detection fashions can help in crop monitoring, pest detection, and yield estimation by figuring out and analyzing objects akin to crops, fruits, or pests in agricultural photographs.
Nevertheless, these are just some there are lots of extra use circumstances the place object detection performs an important position.
Not too long ago, transformer-based detectors have achieved outstanding efficiency by using Imaginative and prescient Transformers (ViT) to course of the multiscale options successfully by separating intra-scale interplay and cross-scale fusion. It’s extremely adaptable, permitting for the versatile adjustment of inference pace by numerous decoder layers with out the necessity for retraining.
To allow real-time object detection, a streamlined hybrid encoder substitutes the unique transformer encoder. This redesigned encoder effectively manages the processing of multi-scale options by separating intra-scale interplay and cross-scale fusion, permitting for efficient characteristic processing throughout completely different scales.
To additional improve the efficiency, IoU-aware question choice is launched throughout the coaching section that gives higher-quality preliminary object queries to the decoder by IoU constraints. Moreover, the proposed detector permits for the handy adjustment of inference pace utilizing completely different decoder layers, leveraging the DETR structure’s decoder design. This characteristic streamlines the sensible utility of the real-time detector with out requiring retraining. Therefore turns into the brand new SOTA for real-time object detection. Actual-time object detectors, which will be roughly labeled into two classes: anchor-based and anchor-free.
- Anchor-Primarily based Object Detectors:
- In anchor-based detectors, predefined anchor packing containers or areas of curiosity are used to foretell the presence of objects and their bounding packing containers.
- These anchor packing containers are generated at numerous scales and side ratios throughout the picture.
- The detector predicts two most important parts for every anchor field: class possibilities (is there an object or not) and bounding field offsets (changes to the anchor field to tightly match the item).
- In style examples of anchor-based detectors embrace Sooner R-CNN, R-FCN (Area-based Totally Convolutional Networks), and RetinaNet.
- Anchor-Free Object Detectors:
- Anchor-free detectors don’t depend on predefined anchor packing containers. As a substitute, they immediately predict bounding packing containers and object presence with out the necessity for anchor packing containers.
- These detectors usually make use of keypoint-based or center-ness prediction strategies.
- Keypoint-based strategies determine key factors (corners, heart, and many others.) and use them to estimate object bounding packing containers.
- Middle-ness prediction focuses on figuring out the probability of a pixel being the middle of an object, and bounding packing containers are constructed based mostly on these facilities.
- In style examples of anchor-free detectors embrace CenterNet and FCOS (Totally Convolutional One-Stage).
Finish to finish object detectors first proposed by Carion et al.an object detector based mostly on Transformer, named DETR (DEtection TRansformer) has efficiently attracted vital consideration as a result of its distinctive options. DETR removes the necessity for hand-designed anchor and Non-Most Suppression (NMS) parts present in conventional detection pipelines. As a substitute, it makes use of bipartite matching and immediately predicts one-to-one object units. This method simplifies the detection pipeline, addressing the efficiency bottleneck related to NMS. Nevertheless, DETR faces challenges, together with gradual coaching convergence and difficulties in optimizing queries.
Use of NMS
Non-Most Suppression (NMS) is a extensively used post-processing algorithm in object detection. It addresses overlapping prediction packing containers by filtering out these with scores under a specified threshold and discarding lower-scored packing containers when their Intersection over Union (IoU) exceeds a second threshold. NMS iteratively processes all packing containers for every class, making its execution time depending on the variety of enter prediction packing containers and the 2 hyperparameters: rating threshold and IoU threshold.
Mannequin Structure
The RT-DETR mannequin includes a spine, a hybrid encoder, and a transformer decoder with auxiliary prediction heads. The structure leverages options from the final three phases of the spine {S3, S4, S5} as enter to the encoder, which makes use of a intra-scale interplay and cross-scale fusion to rework multi-scale options into a picture characteristic sequence. IoU-aware question choice is then utilized to decide on a hard and fast variety of picture options from the encoder output as preliminary queries for the decoder. The decoder, together with auxiliary prediction heads, iteratively refines these queries to generate object packing containers and confidence scores.
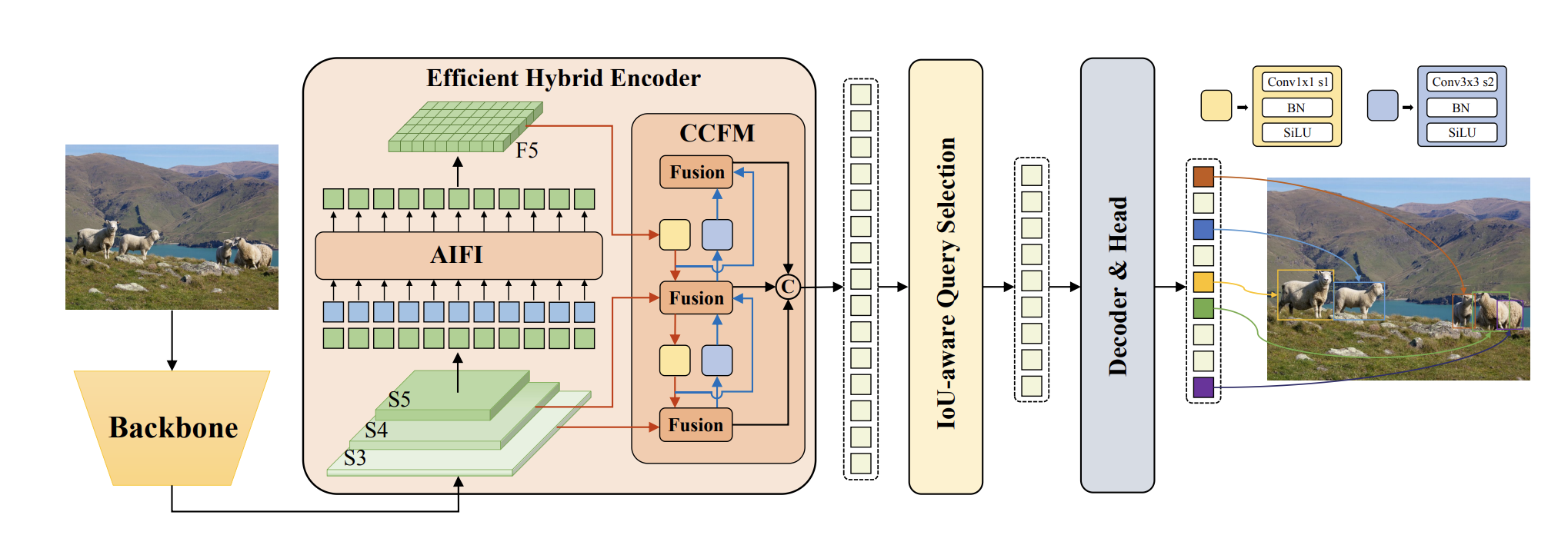
A novel Environment friendly Hybrid Encoder is proposed for RT-DETR. This encoder consists of two modules, the Consideration-based Intrascale Characteristic Interplay (AIFI) module and the CNN based mostly Cross-scale Characteristic-fusion Module (CCFM). Additional, to generate a scalable model of RT-DETR , the ResNet spine was changed with HGNetv2.
Dataset Used
The mannequin was skilled utilizing the COCO train2017 and validated on COCO val2017 dataset. Additional ResNet and HGNetv2 sequence pretrained on ImageNet with SSLD from PaddleClas1 because the spine was used within the mannequin. For IoU-aware question choice, the highest 300 encoder options are chosen to initialize the item queries of the decoder. The coaching technique and hyperparameters of the decoder intently aligns with the DINO method. The detectors had been skilled utilizing AdamW optimizer and information augmentation was carried out with random {color distort, increase, crop, flip, resize} operations.
Comparisons with different SOTA mannequin
The RT-DETR, when in comparison with different real-time and end-to-end object detectors, efficiently demonstrates superior efficiency. Particularly, RT-DETR-L achieves 53.0% Common Precision (AP) at 114 Frames Per Second (FPS), and RT-DETR-X achieves 54.8% AP at 74 FPS. These outcomes outperform present state-of-the-art YOLO detectors by way of each pace and accuracy. Moreover, RT-DETR-R50 achieves 53.1% AP at 108 FPS, and RT-DETR-R101 achieves 54.3% AP at 74 FPS, surpassing the state-of-the-art end-to-end detectors with the identical spine in each pace and accuracy. RT-DETR permits for versatile adjustment of inference pace by making use of completely different decoder layers, all with out requiring retraining. This characteristic enhances the sensible applicability of the real-time detector.
Ultralytics RT-DETR Pre-trained Mannequin
Ultralytics is dedicated to the event of top-notch synthetic intelligence fashions globally. Their open-source initiatives on GitHub showcase state-of-the-art options throughout a various array of AI duties, encompassing detection, segmentation, classification, monitoring, and pose estimation.
Ultralytics Python API supplies pre-trained RT-DETR fashions with completely different scales:
- RT-DETR-L: 53.0% AP on COCO val2017, 114 FPS on T4 GPU
- RT-DETR-X: 54.8% AP on COCO val2017, 74 FPS on T4 GPU
The under instance code snippet presents easy coaching and inference illustrations for RT-DETRR utilizing ultralytics pre-trained mannequin. For complete documentation on these modes and others, seek advice from the pages devoted to Predict, Prepare, Val, and Export within the documentation.
Use pip to put in the bundle.
Carry this mission to life
!pip set up ultralyticsfrom ultralytics import RTDETR
# Load a COCO-pretrained RT-DETR-l mannequin
mannequin = RTDETR('rtdetr-l.pt')
# Show mannequin info (non-compulsory)
mannequin.data()
# Prepare the mannequin on the COCO8 instance dataset for 100 epochs
outcomes = mannequin.practice(information="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the RT-DETR-l mannequin on the 'bus.jpg' picture
outcomes = mannequin('path/to/bus.jpg')
Allow us to examine the inference on a picture and video saved within the native folder!
outcomes = mannequin.predict('https://m.media-amazon.com/photographs/I/61fNoq7Y6+L._AC_UF894,1000_QL80_.jpg', present=True)
outcomes = mannequin.predict(supply="input_video/input_video.mp4", present=True)Conclusions
On this article we mentioned Baidu’s Actual-Time Detection Transformer (RT-DETR), the mannequin stands out for its superior end-to-end object detection, delivering real-time efficiency with out the compromise within the accuracy. RT-DETR harnesses the capabilities of imaginative and prescient transformers to successfully deal with multiscale options. The mannequin’s key options consists of Environment friendly Hybrid Encoder, IoU-aware Question Choice, and Adaptable Inference Velocity. We use the pre-trained mannequin from ultralytics to display the efficiency of the mannequin on photographs and movies. We suggest our readers to click on the hyperlink and get a palms on expertise of this mannequin utilizing the Paperspace platform.
We hope you loved studying the article!
References
RT-DETR (Realtime Detection Transformer)
Uncover the options and advantages of RT-DETR, Baidu’s environment friendly and adaptable real-time object detector powered by Imaginative and prescient Transformers, together with pre-trained fashions.

DETRs Beat YOLOs on Actual-time Object Detection
Not too long ago, end-to-end transformer-based detectors~(DETRs) have achieved outstanding efficiency. Nevertheless, the difficulty of the excessive computational price of DETRs has not been successfully addressed, limiting their sensible utility and stopping them from absolutely exploiting the advantages of no post-processing, akin to non-maximum suppression (NMS). On this paper, we first analyze the affect of NMS in fashionable real-time object detectors on inference pace, and set up an end-to-end pace benchmark. To keep away from the inference delay brought on by NMS, we suggest a Actual-Time DEtection TRansformer (RT-DETR), the primary real-time end-to-end object detector to our greatest information. Particularly, we design an environment friendly hybrid encoder to effectively course of multi-scale options by decoupling the intra-scale interplay and cross-scale fusion, and suggest IoU-aware question choice to enhance the initialization of object queries. As well as, our proposed detector helps flexibly adjustment of the inference pace through the use of completely different decoder layers with out the necessity for retraining, which facilitates the sensible utility of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, whereas RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the identical scale in each pace and accuracy. Moreover, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 instances in FPS. ource code and pre-trained fashions can be found at https://github.com/lyuwenyu/RT-DETR.
GitHub – lyuwenyu/RT-DETR: Official RT-DETR (RTDETR paddle pytorch), Actual-Time DEtection TRansformer, DETRs Beat YOLOs on Actual-time Object Detection. 🔥 🔥 🔥
Official RT-DETR (RTDETR paddle pytorch), Actual-Time DEtection TRansformer, DETRs Beat YOLOs on Actual-time Object Detection. 🔥 🔥 🔥 – GitHub – lyuwenyu/RT-DETR: Official RT-DETR (RTDETR paddle pytorc…
Anchor Bins — The important thing to high quality object detection
A current article got here out evaluating public cloud suppliers’ face detection APIs. I used to be very shocked to see all the detectors fail to…

")