

Semantic segmentation is a pc imaginative and prescient activity that includes classifying every pixel in a picture right into a predefined class. Not like object detection, which identifies objects and attracts bounding packing containers round them, semantic segmentation labels every pixel within the picture, deciding if it belongs to a sure class.
Semantic segmentation has vital significance in varied fields, for instance, in autonomous driving it helps perceive and interpret the environment by figuring out the realm lined by roads, pedestrians, site visitors automobiles, and different objects. In medical fields, it helps phase completely different anatomical constructions (e.g., organs, tissues, tumors) in medical scans, and in agriculture, it’s used for monitoring crops, detecting ailments, and managing sources by analyzing aerial or satellite tv for pc photos.
On this weblog, we are going to look into the structure of a preferred picture segmentation mannequin referred to as DeepLab. However earlier than doing so, we are going to overview how picture segmentation is carried out.
About us: Viso.ai gives the main end-to-end Pc Imaginative and prescient Platform Viso Suite. International organizations use it to develop, deploy, and scale all laptop imaginative and prescient purposes in a single place, with automated infrastructure. Get a private demo.
How is Semantic Segmentation Carried out?
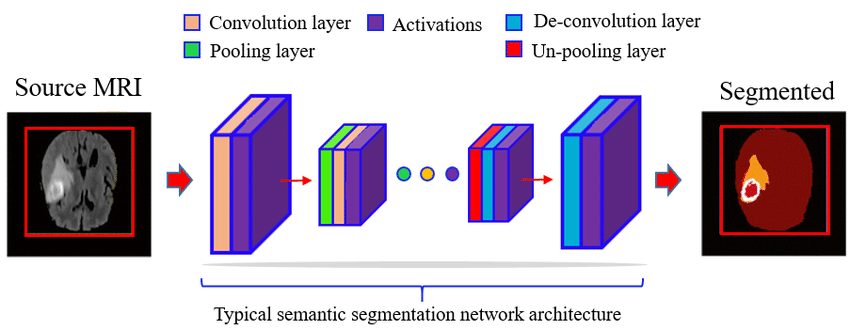
Semantic segmentation includes the next steps:
- Massive datasets of photos with pixel-level annotations (labels) are collected after which used for coaching the segmentation fashions.
- Widespread deep studying architectures embrace Totally Convolutional Networks (FCNs), U-Internet, SegNet, and DeepLab.
- Through the coaching section, the mannequin learns to foretell the category of a single pixel. The mannequin first classifies and localizes a sure object within the picture. Then the pixels within the picture are categorized into completely different classes.
- Then throughout inference, the educated mannequin predicts the category of every pixel in new, unseen photos.
- A number of post-processing strategies are used together with coloring of the picture, which is often seen. Different strategies like Conditional Random Fields (CRFs) are used to refine the segmentation outcomes to make the boundaries smoother and extra correct.
What’s DeepLab Community?
DeepLab is a household of semantic segmentation fashions developed by Google Analysis and is understood for its skill to seize fine-grained particulars and carry out semantic segmentation on high-resolution photos.
This mannequin has a number of variations, every enhancing upon the earlier one. Nevertheless, the core structure of DeepLab stays the identical.
DeepLab v1
DeepLab introduces a number of key improvements for picture segmentation, however some of the essential is using Atrous convolution (Dilated Convolution).
Deep Convolutional Neural Community (DCNN):
DeepLab structure makes use of the VGG-16 deep Convolutional Neural Community as its characteristic extractor, offering sturdy illustration and capturing high-level options for correct segmentation.
Nevertheless, DeepLab v1 replaces the ultimate totally related layers in VGG-16 with convolutional layers and makes use of atrous convolutions. These convolutions enable the community to seize options at a number of scales with out dropping spatial decision, which is essential for correct segmentation.
What’s Atrous Convolution?
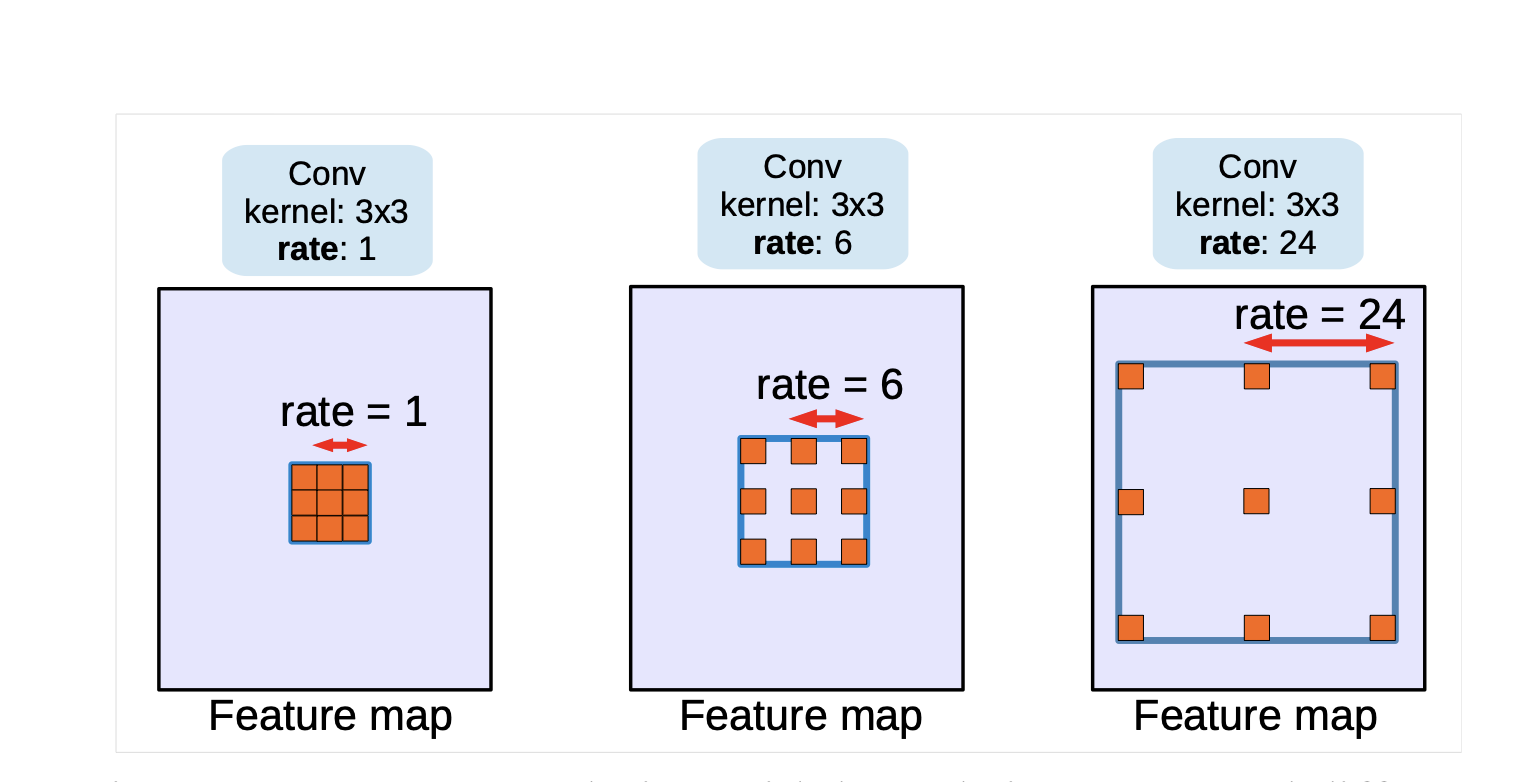
Atrous convolutions are modified variations of normal convolutions, right here the filter is modified to extend the receptive area of the community. Nevertheless, growing the receptive area often ends in an elevated variety of parameters.
Nevertheless, in atrous separable convolution, a rise within the receptive area occurs with out the rise within the variety of parameters or dropping decision, serving to in capturing multi-scale contextual info.
How Does Atrous Convolution Work?
Right here’s how atrous convolution works:
- In a normal convolution, the filter is utilized to the enter characteristic map.
- In an atrous convolution, the filter is utilized with gaps (or holes) between the filter components, that are specified by the dilation charge.
The dilation charge (denoted as r) controls the spacing between the values within the filter. A dilation charge of 1 corresponds to a normal convolution, and a better worth than 1 creates a spot within the filter.
By growing the dilation charge, the receptive area of the convolution expands with out growing the variety of parameters or the computation price.
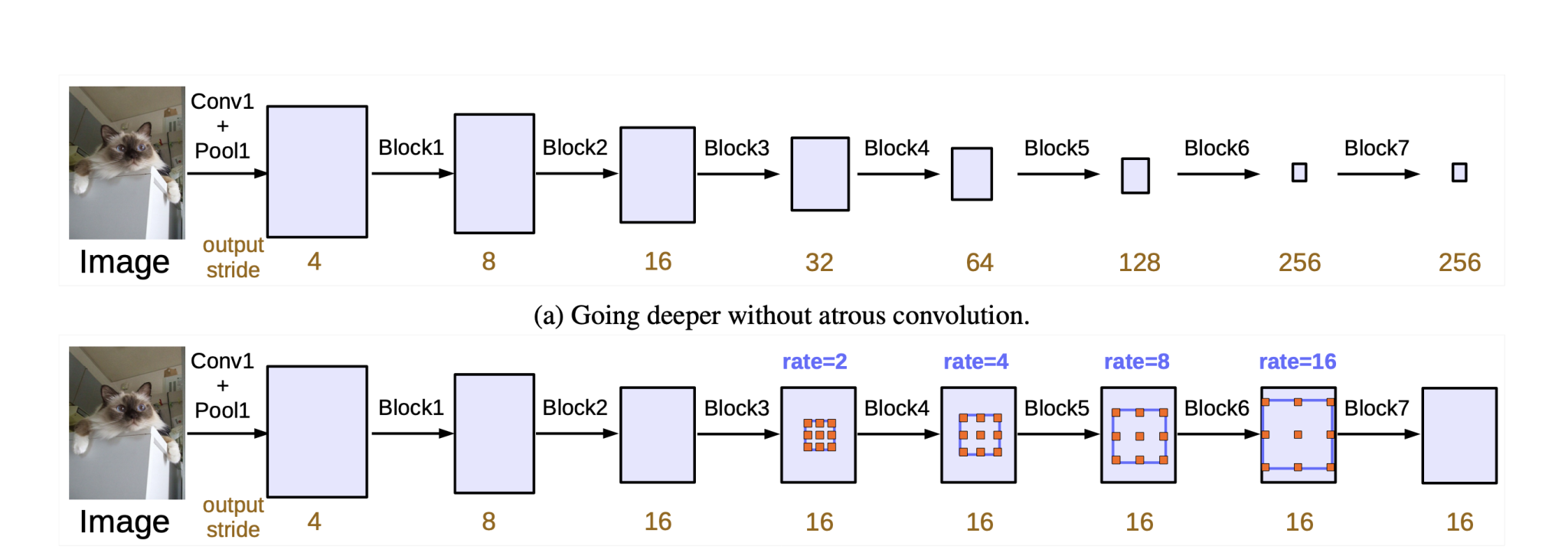
One would possibly assume that the gaps might result in lacking essential options. Nevertheless, in observe, the gaps enable the community to seize multi-scale context effectively. That is significantly helpful for duties like semantic segmentation the place understanding the context round a pixel is essential.
Furthermore, within the later variations of DeepLab, we are able to discover Atrous convolutions mixed with different convolutional layers (each commonplace and atrous) in a community. This mix ensures that options captured at completely different scales and resolutions are built-in, mitigating any potential points from sparse sampling.
CRF Primarily based Submit-processing
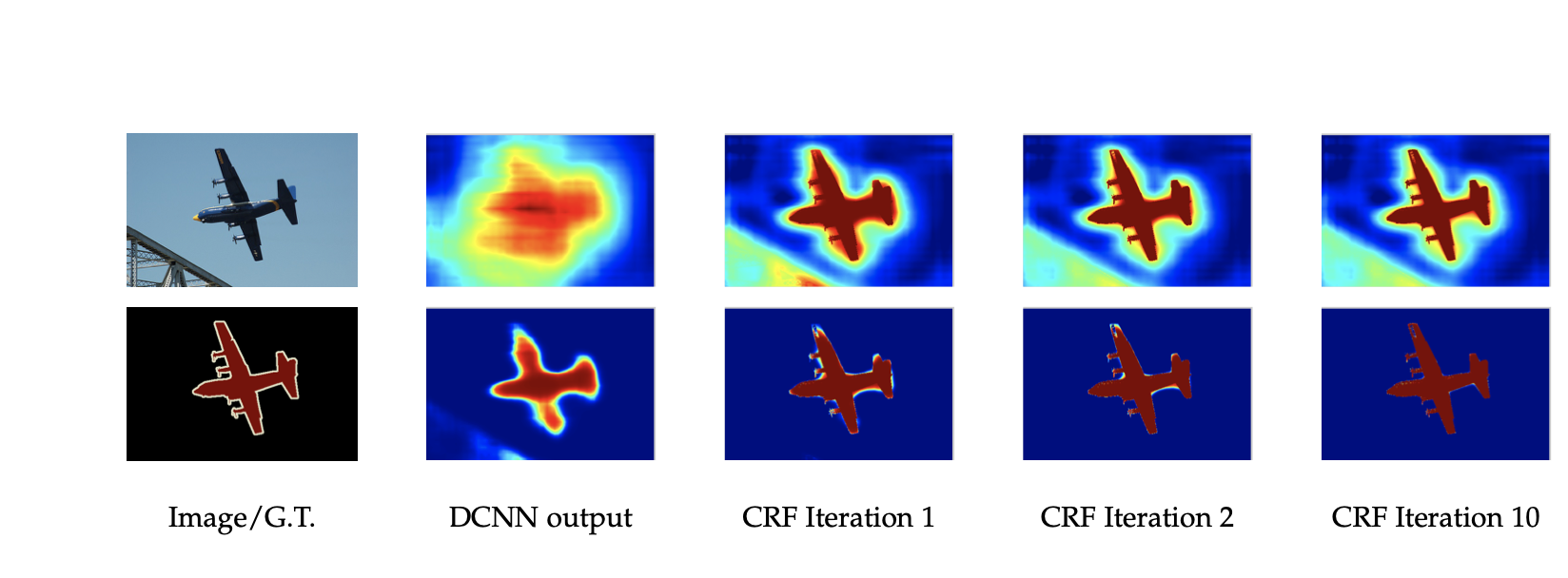
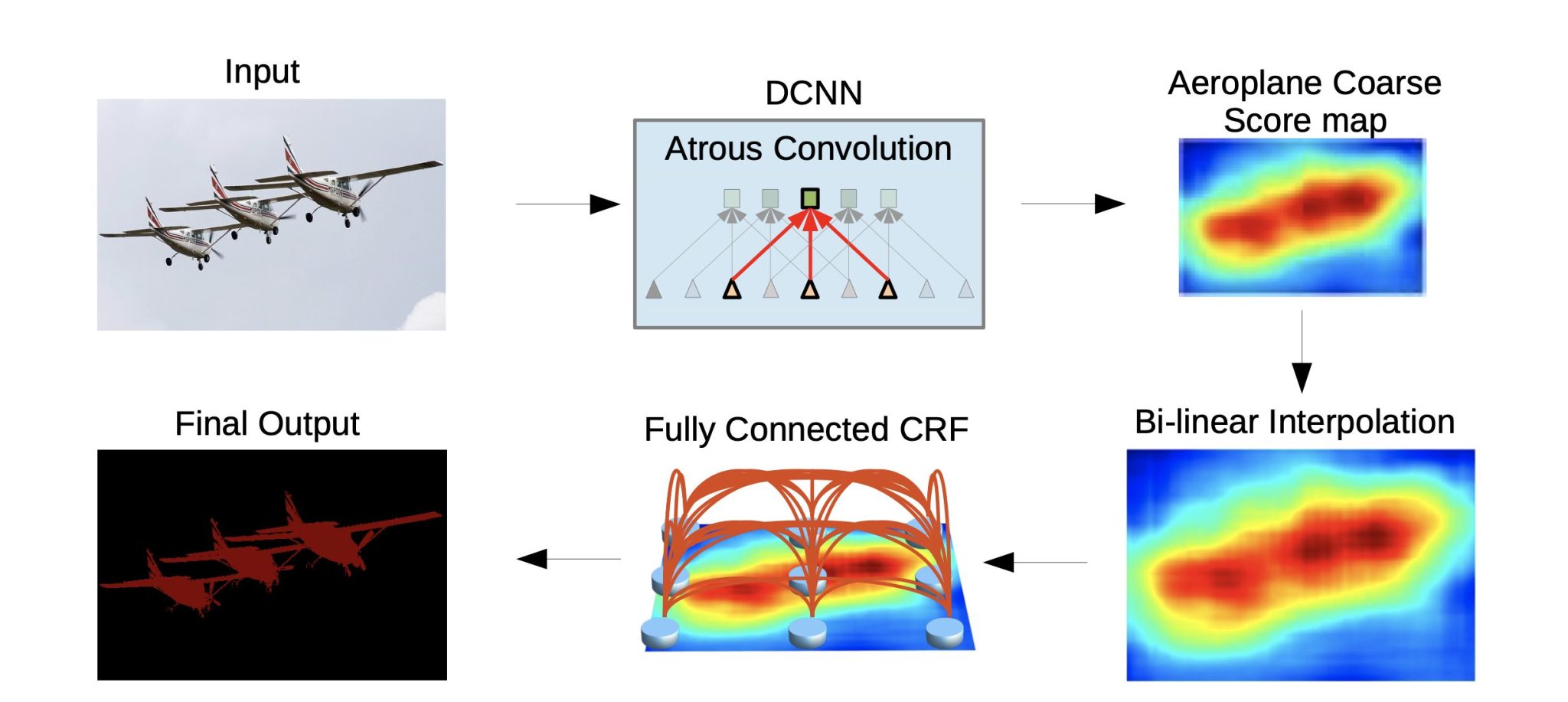
After semantic segmentation is finished, DeepLab makes use of CRF post-processing to refine the segmentation. Conditional Random Discipline (CRF) works as a post-processing step, serving to to sharpen object boundaries and enhance the spatial coherence of the segmentation output. Right here is the way it works:
- The DCNN in DeepLab predicts a chance for every pixel that belongs to a selected class. This generates a preliminary segmentation masks.
- The CRF takes this preliminary segmentation and the picture itself as inputs. It considers the relationships between neighboring pixels and their predicted labels. Then the CRF calculates two kinds of chances:
- Unary Potentials: These characterize the preliminary class chances predicted by the DCNN for every pixel.
- Pairwise Potentials: These seize the relationships between neighboring pixels. They encourage pixels with comparable options or spatial proximity to have the identical label.
By contemplating each these chances, the CRF refines the preliminary segmentation chances.
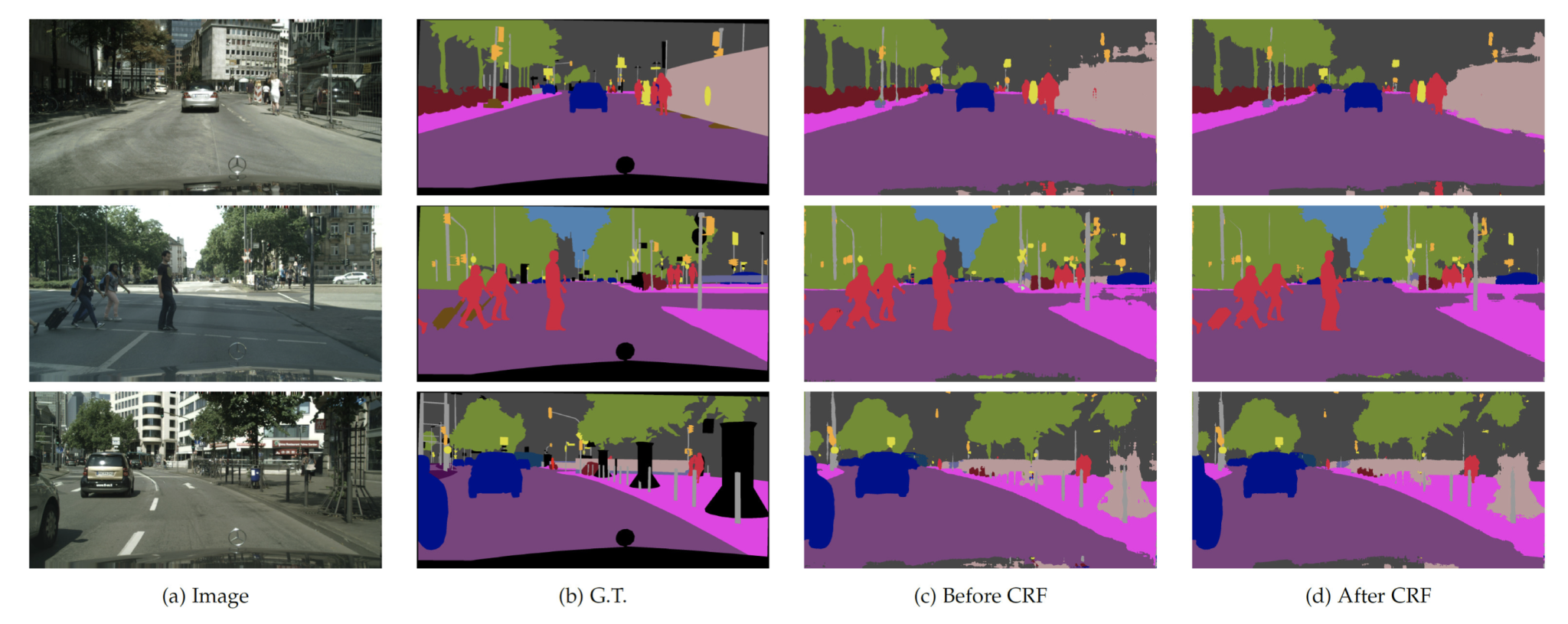
DeepLab v2
DeepLabv2 launched a number of vital enhancements and modifications over its DeepLabv1.
The important thing modifications in DeepLabv2 embrace:
1. Atrous Spatial Pyramid Pooling (ASPP)
One of the crucial notable modifications is the introduction of the Atrous Spatial Pyramid Pooling (ASPP) module.
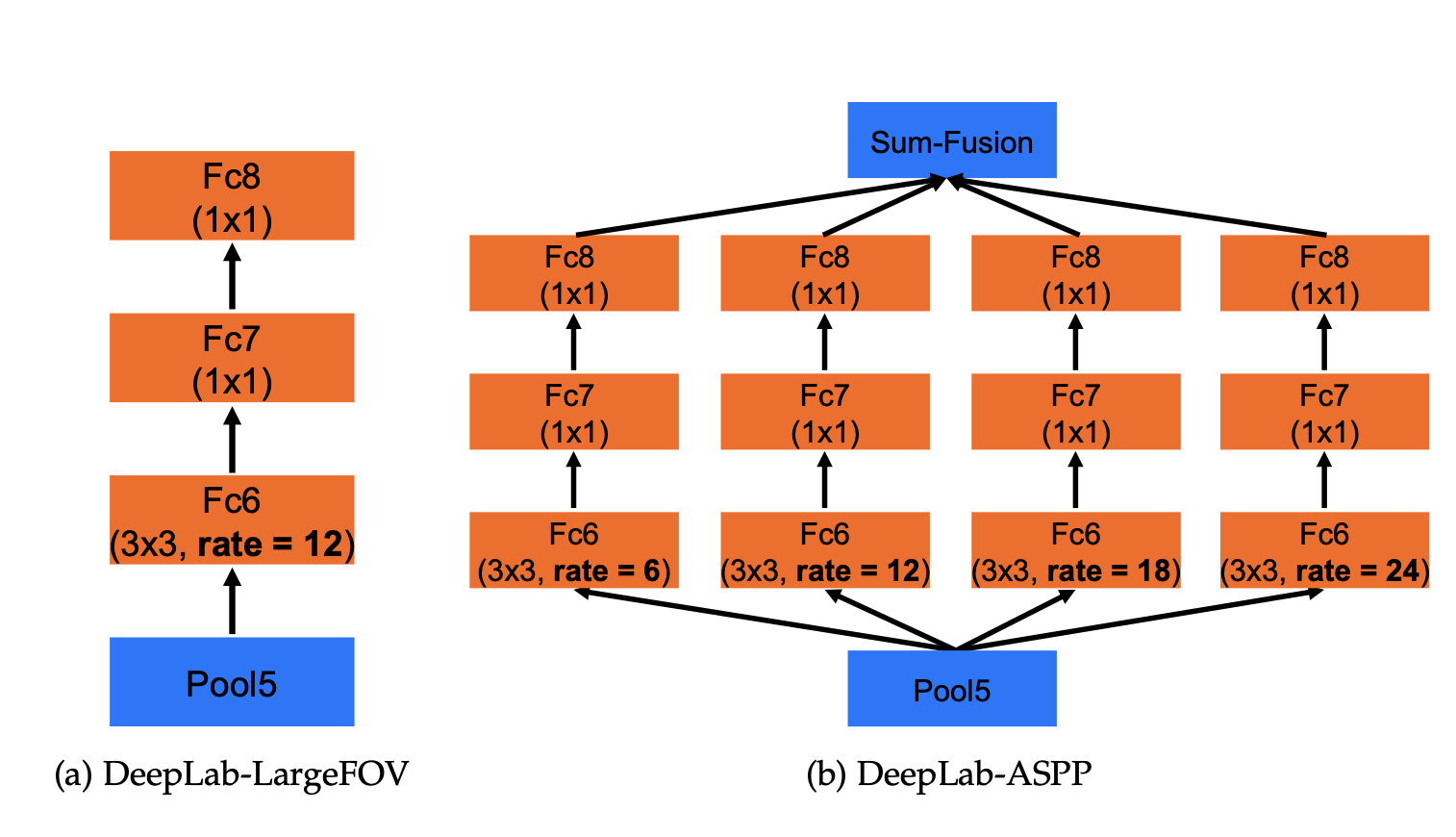
ASPP applies atrous convolution with completely different dilation charges in parallel. This enables it to seize multi-scale info successfully, making the mannequin deal with objects at varied scales and seize world context extra successfully.
Because the DeepLabv1 relied solely on atrous convolutions, they seize info at a specific scale solely relying upon the dilation charge, nevertheless, they miss very small or very giant objects in a picture.
To beat this limitation, DeepLabv2 launched ASPP (which makes use of a number of atrous convolutions with completely different strides aligned in parallel). Right here is how It really works:
- The enter characteristic map is fed into a number of atrous convolution layers, every with a special dilation charge.
- Every convolution with a selected charge captures info at a special scale. A decrease charge focuses on capturing finer particulars (smaller objects), whereas a better charge captures info over a bigger space (bigger objects).
- Ultimately, the outputs from all these atrous convolutions are concatenated. This mixed output incorporates options from varied scales, making the community higher in a position to perceive objects of various sizes inside the picture.
2. DenseCRF
DeepLabv2 improves the CRF-based post-processing step through the use of a DenseCRF, which extra precisely refines the segmentation boundaries, because it makes use of each pixel-level and higher-order potentials to boost the spatial consistency and object boundary delineation within the segmentation output.
Normal CRFs will be utilized to numerous duties that aren’t associated to laptop imaginative and prescient. In distinction, DenseCRF is particularly designed for picture segmentation, the place all pixels are thought of neighbors in a completely related graph. This enables it to seize the spatial relationships between all pixels and their predicted labels.
3. Deeper Spine Networks
Whereas DeepLabv1 makes use of architectures like VGG-16, DeepLabv2 incorporates deeper and extra highly effective spine networks akin to ResNet-101. These deeper networks present higher characteristic representations, contributing to extra correct segmentation outcomes.
4. Coaching with MS-COCO
DeepLabv2 contains coaching on the MS-COCO dataset along with the PASCAL VOC dataset, serving to the mannequin to generalize higher and carry out on numerous and sophisticated eventualities.
DeepLab v3
DeepLabv3 additional improves upon DeepLab v2, enhancing the efficiency and accuracy of semantic segmentation. The principle modifications in DeepLabv3 embrace:
1. Enhanced Atrous Spatial Pyramid Pooling (ASPP)
DeepLabv3 refines the ASPP module by incorporating batch normalization and utilizing each world common pooling with the already launched, atrous convolution with a number of dilation charges.
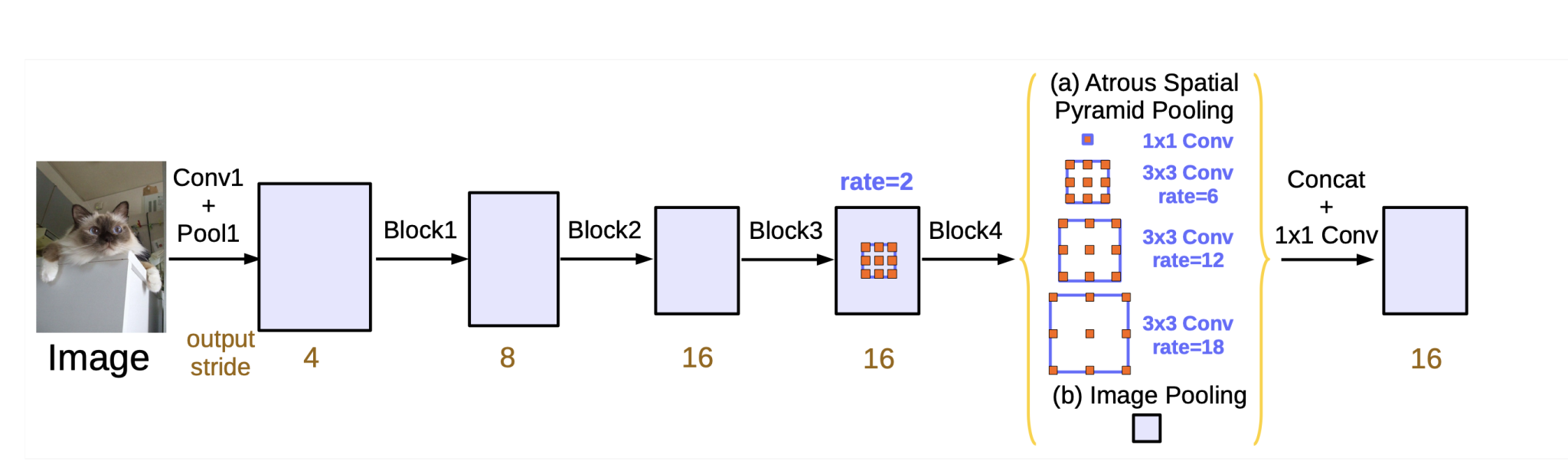
2. Deeper and Extra Highly effective Spine Networks
DeepLabv3 makes use of even deeper and extra highly effective spine networks, akin to ResNet, and the extra computationally environment friendly Xception structure. These backbones supply improved characteristic extraction capabilities, which contribute to higher segmentation efficiency.
3. No Specific Decoder
Though encoder-decoder structure is sort of widespread in segmentation duties, DeepLabv3 achieves glorious efficiency utilizing a less complicated design with no particular decoder stage. The ASPP and have extraction layers present ample efficiency to seize and course of info.
4. International Pooling
The ASPP module in DeepLabv3 contains world common pooling, which captures world context info and helps the mannequin perceive the broader scene structure. This operation takes all the characteristic map generated by the spine community and squeezes it right into a single vector.
That is carried out to seize image-level options, as these characterize the general context of the picture, summarizing all the picture and scene. That is essential for DeepLab semantic picture segmentation, because it helps the mannequin perceive the relationships between completely different objects within the picture.
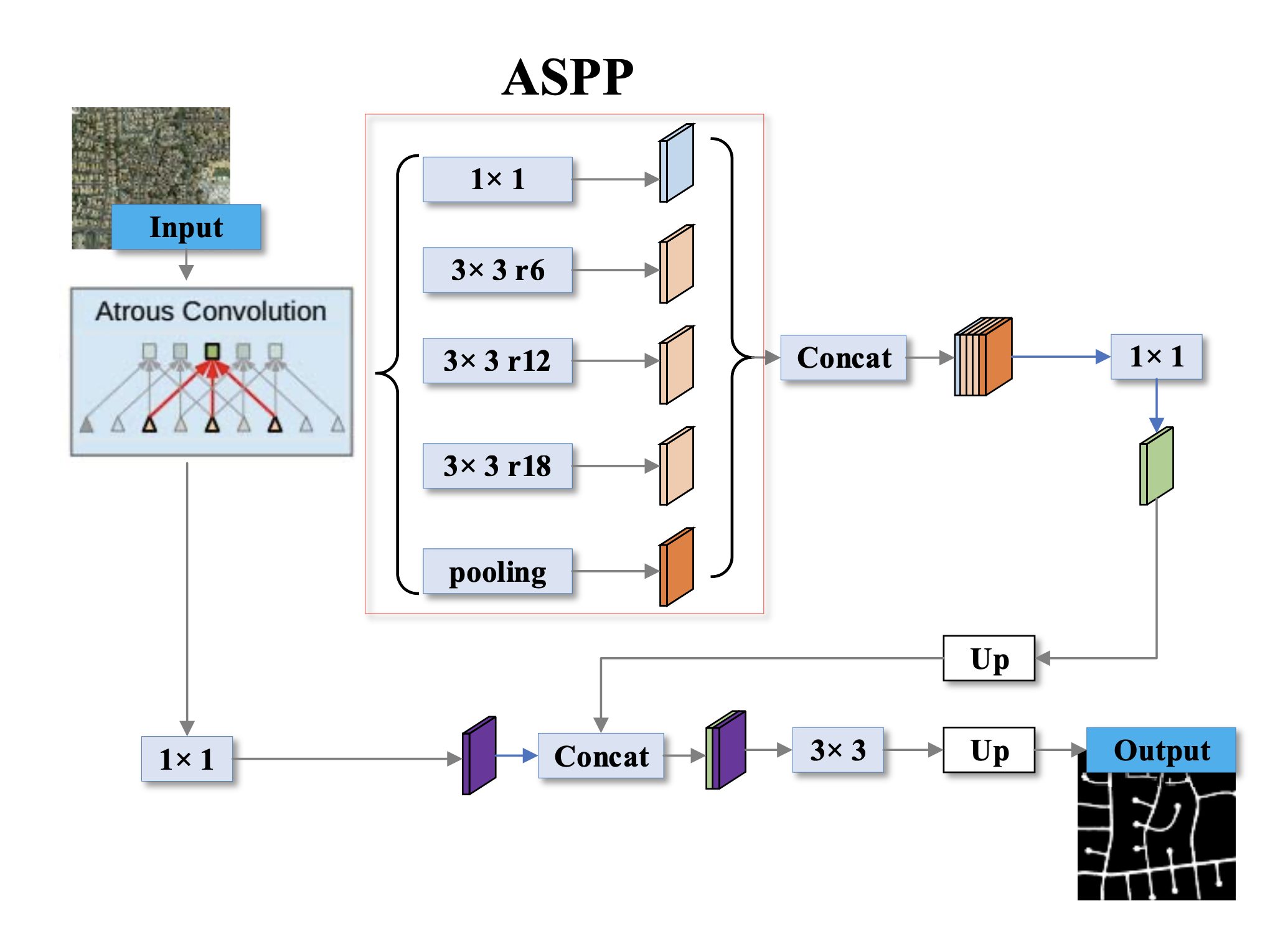
5. 1×1 Convolution
DeepLabv3 additionally introduces 1×1 convolution. In common convolutions, the filter has a measurement bigger than 1×1. This filter slides throughout the enter picture, performing element-wise multiplication and summation with the overlapping area of the picture to generate a brand new characteristic map.
A 1×1 convolution, nevertheless, makes use of a filter of measurement 1×1. This implies it considers solely a single pixel at a time from the enter characteristic map.
Whereas this would possibly appear to be a easy operation that doesn’t seize a lot info, nevertheless, 1×1 convolutions supply a number of benefits:
- Dimensionality Discount: A key profit is the flexibility to cut back the variety of channels within the output characteristic map. By making use of a 1×1 convolution with a selected variety of output channels, the mannequin can compress the data from a bigger variety of enter channels. This helps management mannequin complexity and probably cut back overfitting throughout coaching.
- Characteristic Studying: The 1×1 convolution acts as a characteristic transformation layer, making the mannequin study a extra compact and informative illustration of the image-level options. It could possibly emphasize probably the most related elements of the worldwide context for the segmentation activity.
That is how world common pooling and 1×1 convolution are utilized in deepLabv3:
- DeepLabv3 first performs world common pooling on the ultimate characteristic map from the spine.
- The ensuing image-level options are then handed by way of a 1×1 convolution.
- This processed model of the image-level options is then concatenated with the outputs from atrous convolutions with completely different dilation charges (one other part of ASPP).
- The mixed options present a wealthy illustration that includes each native particulars captured by atrous convolutions and world context captured by the processed image-level options.
Conclusion
On this weblog, we seemed on the DeepLab neural community collection and the numerous developments made within the area of picture segmentation.
DeepLab picture segmentation mannequin laid the muse with the introduction of atrous convolution, which allowed for capturing multi-scale context with out growing computation. Furthermore, It employed a CRF for post-processing to refine segmentation boundaries.
The DeepLabv2 Improved upon DeepLabv1 by introducing the Atrous Spatial Pyramid Pooling (ASPP) module, which allowed for multi-scale context aggregation. Furthermore, using deeper spine networks and coaching on bigger datasets like MS-COCO contributed to higher efficiency. The DenseCRF refinement step improved spatial coherence and boundary accuracy.
The third model, DeepLabv3, additional refined the ASPP module by incorporating batch normalization and world common pooling for even higher multi-scale characteristic extraction and context understanding. DeepLabv3 makes use of even deeper and extra environment friendly spine networks just like the Xception community.
To study extra about laptop imaginative and prescient, we advise testing our different blogs:
")