

Pascal VOC is a famend dataset and benchmark suite that has considerably contributed to the development of laptop imaginative and prescient analysis. It gives standardized picture information units for object class recognition and a standard set of instruments for accessing the info and evaluating the efficiency of laptop imaginative and prescient fashions.
This text provides you with a complete overview of Pascal VOC, its dataset improvement through the years, and lots of extra.
All through the article you’ll acquire the next information:
- What’s Pascal VOC and its Significance?
- Targets and Motivation Driving Pascal VOC Dataset Improvement
- How Pascal VOC Datasets Have Propelled CV Analysis
- Improvement of Pascal VOC Datasets Over the Years (From 2005 to 2012)
- Key CV Duties Supported by Pascal VOC
- Notable Methodologies and Fashions Evaluated on Pascal VOC
- Limitations
- Transition to Extra Superior Datasets like COCO and OpenImages
- Future Instructions within the Discipline of Pc Imaginative and prescient
About us: Viso.ai gives a sturdy end-to-end laptop imaginative and prescient infrastructure – Viso Suite. Our software program helps a number of main organizations begin with laptop imaginative and prescient and implement deep studying fashions effectively with minimal overhead for varied downstream duties. Get a demo right here.
What’s Pascal VOC?
Pascal VOC (which stands for Sample Evaluation, Statistical Modelling, and Computational Studying Visible Object Lessons) is an open-source picture dataset for a lot of visible object recognition algorithms.
It was initiated in 2005 as a part of the Pascal Visible Object Lessons Problem. This problem was performed until 2012, every subsequent yr. The VOC dataset consists of practical pictures collected from varied sources together with the web and private images.
Every picture within the datasets is fastidiously annotated with bounding containers, segmentation masks, and labels for varied object classes. These annotations henceforth function floor fact information that allows supervised studying approaches and facilitates the event of superior laptop imaginative and prescient fashions.

Targets and Motivation Behind Pascal VOC Problem
The Pascal VOC promotes analysis and improvement within the discipline of visible object classification. Its main function was to offer reference information units, benchmarks for evaluating efficiency, and a working platform for the analysis involving the detection and recognition of objects. The challenge centered on object lessons in practical scenes; thus, the examined pictures included cluttered backgrounds, occlusion, and varied object orientations.
Because of Pascal VOC, researchers, and builders had been capable of examine varied algorithms and strategies on an entity foundation. This helped in enhancing the article classification strategies and successfully stimulated the interplay and trade of concepts among the many laptop imaginative and prescient specialists. Thus, the annotated pictures with their floor fact labels, collected because the challenge’s datasets, will be thought to be substantial benchmarks for coaching and testing the article detection and recognition fashions that had been so essential for advancing this discipline of laptop imaginative and prescient.
Pascal VOC Dataset Improvement
The Pascal VOC dataset was developed from 2005 to 2012. Every year, a brand new dataset was launched for classification and detection duties.
Right here’s a short overview of the dataset improvement:
VOC2005
The VOC2005 problem goals to establish objects from completely different classes in real-world scenes (not pre-segmented or remoted objects). It’s basically a supervised studying job, which means a labeled picture dataset might be offered to coach the article recognition mannequin.
Here’s a breakdown of this problem statistics:
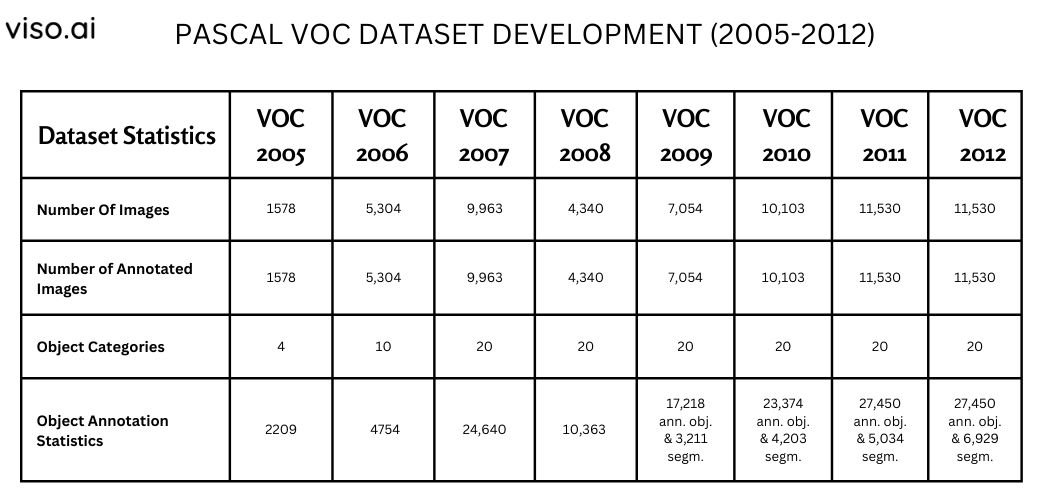
- Quantity Of Photographs: 1578
- Variety of annotated pictures: 1578
- Object Classes: 4 Lessons (Embrace the views of motorbikes, bicycles, individuals, and automobiles in arbitrary pose)
- Object annotation statistics: Comprises 2209 annotated objects.
- Annotation Notes: Photographs had been largely taken from present public datasets. This dataset is now out of date.

VOC2006
The VOC2006 problem tasked members with recognizing varied object varieties in real-world scene pictures, quite than simply pre-segmented objects. It was a supervised studying studying drawback that included 10 object lessons and greater than 5 thousand pre-trained units of labeled pictures.
In contrast to the earlier model (VOC2005) with clear backgrounds, VOC2006 presents a more durable problem. Its dataset pictures embrace objects which are partially hidden behind different objects (occlusions), filled with stuff (muddle), and captured from completely different angles (views). This made VOC2006 extra practical but in addition a lot more durable to resolve.
Right here is the precise breakdown of this dataset’s statistics:
- Quantity Of Photographs: 5,304
- Variety of annotated pictures: 5,304
- Object Classes: 10 Lessons (It contains the views of bicycles, buses, cats, automobiles, cows, canine, horses, motorbikes, individuals, and sheep in arbitrary poses.)
- Object annotation statistics: Comprises 4754 annotated objects.
VOC2007
VOC2007 constructed on prior VOC challenges for object recognition in pure pictures. It expanded the dataset dimension and added a brand new job of pixel-wise object occasion segmentation. The take a look at information was tougher, that includes elevated range and complexity. Analysis metrics had been enhanced to investigate localization accuracy higher and quantify efficiency throughout differing object truncation and occlusion ranges.
General, VOC2007 raised the bar with its bigger scale, occasion segmentation job, and extra complete benchmarking of object detection and segmentation capabilities in practical scenes.
Listed below are the dataset statistics of VOC2007:
- Quantity Of Photographs: 9,963
- Variety of annotated pictures: 9,963
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, television/monitor

- Object annotation statistics: Comprises 24,640 annotated objects
- Annotation Notes: This yr, they got here up with a set of 20 classes that haven’t modified since. It was additionally the final yr they launched class labels for the take a look at information.
VOC2008
Whereas VOC2008 didn’t introduce new duties or lessons in comparison with VOC2007, it offered a contemporary and sizeable annotated dataset of 4,340 pictures containing 10,363 labeled object cases throughout 20 classes. A key facet of VOC2008 was the provision of pixel-wise segmentation annotations for all object cases, along with bounding containers. Furthermore, the dataset maintained a 50-50 trainval-test break up, with standardized analysis metrics like imply Common Precision (mAP) for rating detection efficiency throughout Pascal VOC lessons and intersection over union (IoU) for segmentation high quality.
Listed below are the dataset statistics of VOC2008:
- Quantity Of Photographs: 4,340
- Variety of annotated pictures: 4,340
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, television/monitor
- Object annotation statistics: Comprises 10,363 annotated objects
VOC2009
The VOC2009 accommodates 7,054 annotated pictures, practically double the scale of VOC2008. Throughout these pictures, there have been 17,218 annotated object cases from the identical 20 lessons masking individuals, animals, autos, and indoor objects.
This problem has made this important change to the principles:
Take a look at set annotations remained confidential. This implies researchers needed to develop algorithms that ought to excel in unseen information.
Listed below are the dataset statistics of VOC2009:
- Quantity Of Photographs: 7,054
- Variety of annotated pictures: 7,054
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, television/monitor
- Object annotation statistics: Include 17,218 ROI annotated objects and three,211 segmentations.
- Annotation Notes: There have been no particular directions for the additional pictures. Furthermore, the take a look at information labels weren’t accessible.
VOC2010
VOC2010 additional scaled up the benchmark, offering 10,103 annotated pictures – a 43% enhance over VOC2009. These pictures contained 23,374 annotated object cases throughout the identical twenty object lessons, together with 4,203 pixel-wise segmentation masks.
This problem has made this important change to the principles:
As a substitute of counting on pre-made samples, researchers are supposed to make use of all accessible information factors that guarantee a extra correct analysis of CV algorithms.
Nevertheless, like VOC2009, coaching validation, and take a look at set annotations weren’t publicly launched. With its bigger annotated Pascal VOC dataset dimension and up to date analysis protocol, VOC2010 offered a extra complete and sturdy benchmark for assessing object recognition capabilities on complicated, real-world imagery at an elevated scale.
These had been the dataset statistics:
- Quantity Of Photographs: 10,103
- Variety of annotated pictures: 10,103
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, television/monitor
- Object annotation statistics: Comprises 23,374 ROI annotated objects and 4,203 segmentations.
- Annotation Codecs: The best way Common Precision (AP) is calculated has been up to date. As a substitute of utilizing a sampling technique like TREC, all information factors at the moment are included within the calculation. Moreover, in that problem, the annotations for the take a look at information weren’t publicly accessible.
VOC2011
PASCAL VOC problem took an enormous step ahead in 2011 with VOC2011. This dataset launched an enormous quantity of information that included 11,530 pictures – the most important assortment.
It encompasses a dataset with 27,450 labeled object cases throughout 20 lessons. It additional gives 5,034 cases with pixel-wise segmentation masks. All the principles had been the identical as that of VOC2010.
These had been the VOC2011’s dataset statistics:
- Quantity Of Photographs: 11,530
- Variety of annotated pictures: 11,530
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, television/monitor
- Object annotation statistics: Comprises 27,450 ROI annotated objects and 5,034 segmentations.
- Annotation Notes: The method to calculating common precision (AP) has modified. As a substitute of utilizing a selected sampling technique (TREC), it now considers all accessible information factors. Moreover, annotations for the prepare information are now not publicly accessible.
VOC2012
The Pascal VOC2012 datasets for classification, detection, and particular person format are the identical as VOC2011. No extra information has been annotated. It additionally included practically 28,000 labeled objects from a lot of 20 completely different classes. These objects had been marked with bounding containers and Pascal VOC segmentation masks that make it simpler for computer systems to acknowledge objects.
This vital enhance in information made VOC2012 a more durable take a look at for object recognition algorithms. The dataset challenged these algorithms to carry out effectively on real-world pictures with extra objects and complexity, all whereas utilizing the identical analysis strategies.

These had been the VOC2012’s dataset statistics:
- Quantity Of Photographs: 11,530
- Variety of Annotated Photographs: 11,530
- Object Classes: 20 Lessons
It contains:
Individual: particular person
Animal: fowl, cat, cow, canine, horse, sheep
Car: aeroplane, bicycle, boat, bus, automobile, bike, prepare
Indoor: bottle, chair, eating desk, potted plant, couch, TV/monitor
- Object annotation statistics: Comprises 27,450 ROI annotated objects and 6,929 segmentations.
- Annotation Notes: The dataset for classification, detection, and particular person format duties stays unchanged from VOC2011.
Key Duties Supported by Pascal VOC
The Pascal VOC datasets assist and consider varied laptop imaginative and prescient duties, together with:
Object Classification
The Pascal VOC dataset helps object classification by offering labeled pictures with a number of object classes, enabling coaching and analysis of fashions that assign a single label to a whole picture based mostly on the article’s presence.

Object Detection
For object detection, the dataset has pictures that present annotated bounding containers round objects to assist the fashions study which classes of objects to establish and their positions in pictures.
Picture Segmentation
Some pictures have ground-truth pixel-level annotations, which permit for semantic segmentation the place the mannequin fashions section and classify particular person pixels, exactly delineating object boundaries.

Motion Classification
The dataset accommodates annotations for human actions that allow the coaching and analysis of motion classification fashions. They’ll establish and differentiate between varied human actions or interactions with objects inside pictures.
Notable Methodologies And Fashions Evaluated On Pascal VOC
The Pascal VOC datasets served as a testbed for varied laptop imaginative and prescient methodologies and fashions, starting from conventional approaches to deep studying methods. Listed below are some notable examples:
Conventional Approaches
- Sliding Window Detectors: This technique makes use of a fixed-size window to check object presence elsewhere of the picture. The examples embrace Viola-Jones detectors and Histogram of Oriented Gradients detectors.
- Bag-of-Visible-Phrases Fashions: These fashions represented pictures as histograms of visible phrases, and every visible phrase from the histogram corresponded to a neighborhood picture patch or texture characteristic. The 2 most acknowledged and probably efficient approaches are Spatial Pyramid Matching (SPM) and Bag of Visible Phrases (BoVW).
- Deformable Half-based Fashions: These fashions labored on the idea that objects had been made up of a smaller variety of geometric items that could possibly be distorted, which made the fashions extra versatile. An instance of such representations is constituted by the Deformable Half Mannequin launched by Felzenszwalb et al.
Deep Studying Approaches
- Convolutional Neural Networks (CNNs): The CNNs together with AlexNet, VGGNet, and ResNet helped remedy laptop imaginative and prescient issues by studying the hierarchal options instantly from the Pascal VOC information. These fashions had been capable of set benchmark accuracy on the Pascal VOC classification and detection challenges.
- Area-based Convolutional Neural Networks (R-CNNs): Quick R-CNN and Sooner R-CNN fashions built-in area proposal methods with CNNs for object detection and localization with very excessive accuracy on Pascal VOC datasets.
- You Solely Look As soon as (YOLO): The YOLO mannequin offered a unified technique of detection of the article. YOLO, together with its variants had been examined on Pascal VOC datasets and demonstrated excessive efficiency and real-time capabilities.
- Masks R-CNN: Masks R-CNN is an extension of the Sooner R-CNN mannequin. It predicts segmentation masks for state-of-art occasion segmentation on Pascal VOC datasets.
Transition To Newer Datasets
Over time, laptop imaginative and prescient research and deep studying algorithms developed, and the restrictions of Pascal VOC datasets grew to become more and more noticeable. Researchers additionally noticed a requirement for elevated and extra various benchmarks and higher-quality annotations which are vital for additional improvement of the sector.
COCO
The COCO dataset was created in 2014 and it was a lot bigger with over 300,000 pictures describing 80 classes of objects and detailed annotations, together with occasion segmentation masks and captions.
OpenImages
The OpenImages dataset accommodates over 9 million coaching pictures with bounding containers, segmentation masks, and visible relationships. It gives selection and issue since it may be used for a number of laptop imaginative and prescient.
Future Instructions
The Pascal VOC has a promising future in laptop imaginative and prescient. As the sector advances, there might be a necessity to make use of bigger, extra numerous, and tougher datasets to drive the sector ahead. Any information with extra sophisticated eventualities from multi-modal information to real-world conditions might be important for coaching common and secure studying fashions.
To sum up, benchmark datasets like Pascal VOC certainly play an vital function in laptop imaginative and prescient research. We anticipate to see additional developments of Pascal VOC benchmark datasets enhancing the machine studying area.
What’s Subsequent?
As laptop imaginative and prescient analysis progresses and new challenges emerge, the event of extra numerous, complicated, and large-scale datasets might be crucial for pushing the boundaries of what’s potential. Whereas the Pascal VOC dataset has performed a pivotal function in shaping the sector, the long run lies in embracing new datasets and benchmarks that higher replicate the range and complexity of the true world.
To study extra about laptop imaginative and prescient and machine studying, we recommend testing our different blogs:
Actual-time Pc Imaginative and prescient Purposes
We developed Viso Suite for real-time enterprise laptop imaginative and prescient functions. Viso Suite is the one totally end-to-end laptop imaginative and prescient infrastructure, managing your entire software improvement course of from information assortment to deployment to safety. Thus, eliminating the necessity for level options. To see what Viso Suite can do for you, e book a demo with our crew.
")