

Apple Machine Studying analysis launched a set of Autoregressive Picture Fashions (AIM) earlier this yr. The gathering of various mannequin sizes, ranging from a number of hundred million parameters, up to a couple billion.
The research geared toward visualizing the coaching performances of the fashions scaled in dimension. This text will discover the completely different experiments, datasets used, and derived conclusions. Nonetheless, first, we should perceive autoregressive modeling and its use in picture modeling.
About us: Viso Suite is a versatile and scalable infrastructure developed for enterprises to combine laptop imaginative and prescient into their tech ecosystems seamlessly. Viso Suite permits enterprise ML groups to coach, deploy, handle, and safe laptop imaginative and prescient functions in a single interface.
Autoregressive Fashions
Autoregressive fashions are a household of fashions that use historic information to foretell future information factors. They study the underlying patterns of the info factors and their causal relationships to foretell future information factors. Common examples of autoregressive fashions embrace Autoregressive Built-in Shifting Common (ARIMA) and Seasonal Autoregressive Built-in Shifting Common (SARIMA). These fashions are principally utilized in time-series forecasting in gross sales and income.
Autoregressive Picture Fashions
Autoregressive Picture Modeling (AIM) makes use of the identical method however on picture pixels as information factors. The method divides the picture into segments and treats the segments as a sequence of knowledge factors. The mannequin learns to foretell the following picture phase given the earlier information level.
Common fashions like PixelCNN and PixelRNN (Recurrent Neural Networks) use autoregressive modeling to foretell visible information by inspecting current pixel data. These fashions are utilized in functions resembling picture enhancement. A few of these functions embrace upscaling and generative networks to create new pictures from scratch.
Pre-training Giant-Scale Autoregressive Picture Fashions
Pre-training an AI mannequin includes coaching a large-scale basis mannequin on an intensive and generic dataset. The coaching process can revolve round pictures or textual content relying on the duties the mannequin is meant to unravel.
Autoregressive picture fashions take care of picture datasets and are pre-trained on standard datasets like MS COCO and ImageNet. The researchers at Apple used the DFN dataset launched by Fang et al. Let’s discover the dataset intimately.
Dataset
The dataset includes 12.8 billion image-text pairs filtered from the Widespread Crawl dataset (text-to-image fashions). This dataset is additional filtered to take away not secure for work content material, blur faces, and take away duplicated pictures. Lastly, alignment scores are calculated between the photographs and the captions and solely the highest 15% of knowledge parts are retained. The ultimate subset incorporates 2 billion cleaned and filtered pictures, which the authors label as DFN 2B.
Structure
The coaching method stays the identical as that of ordinary autoregressive fashions. The enter picture is split into Okay equal components and organized in a linear mixture to type a sequence. Every picture phase acts as a token, and in contrast to language modeling, the structure offers with a set variety of segments.

The picture segments are handed to a transformer structure, which makes use of self-attention to know the pixel data. All future tokens are masked through the self-attention mechanism to make sure the mannequin doesn’t ‘cheat’ through the coaching.
A easy multi-layer perceptron is used because the prediction head on prime of the transformer implementation. The 12-block MLP community tasks the patch options to pixel area for the ultimate predictions. This head is barely utilized throughout pre-training and changed throughout downstream duties in line with activity necessities.
Experimentation
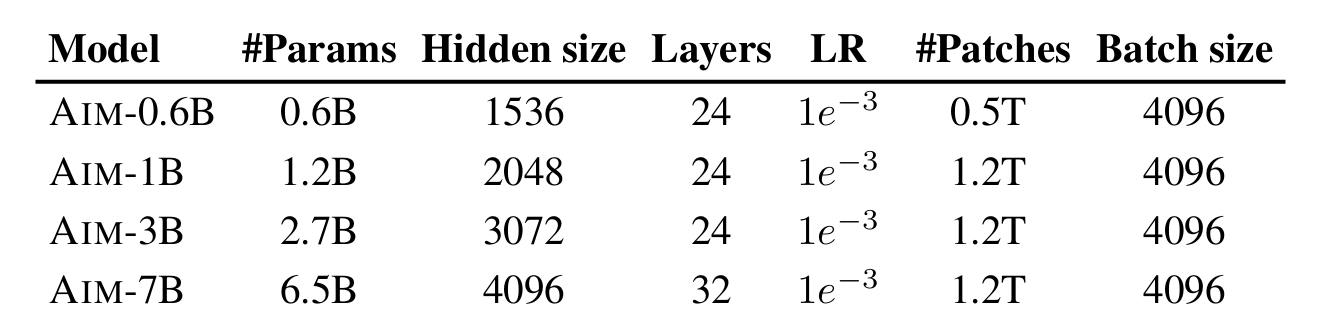
A number of variations of the Autoregressive Picture Fashions had been created with variations in peak and depth. The fashions are curated with completely different layers and completely different hidden items inside every layer. The mixtures are summarised within the desk beneath:
The coaching can also be carried out on different-sized datasets, together with the DFN-2B mentioned above and a mixture of DFN-2B and IN-1k known as DFN-2B+.
Outcomes
The completely different era fashions had been examined and noticed for efficiency throughout a number of iterations. The outcomes are as follows:
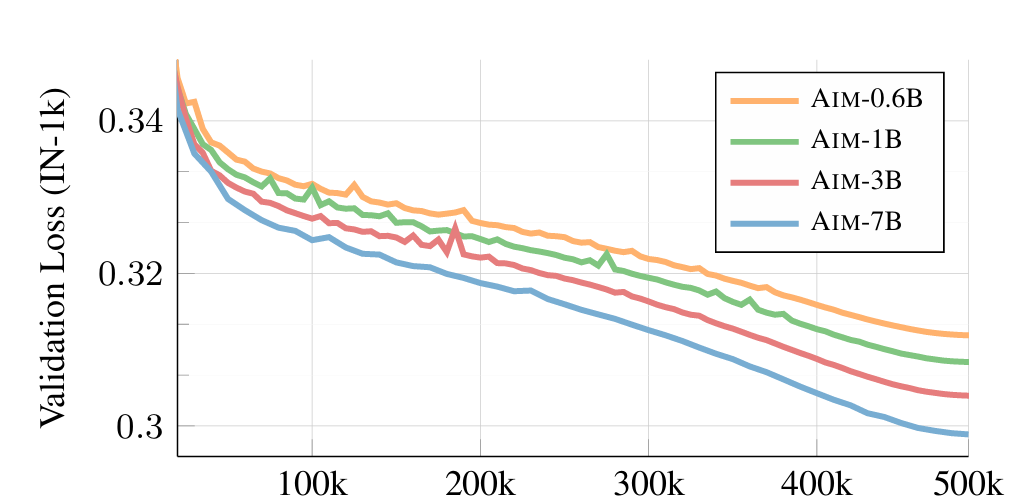
- Altering Mannequin Measurement: The experiment reveals that rising mannequin parameters barely improves the coaching efficiency. The loss reduces rapidly, and the fashions carry out higher because the parameters improve.
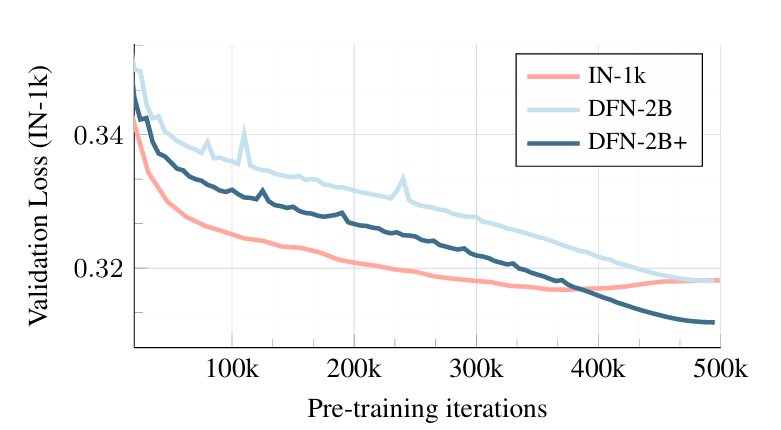
- Coaching Knowledge Measurement: The AIM-0.6B mannequin is educated in opposition to three dataset sizes to watch validation loss. The smallest information set IN-1k begins with a decrease validation loss that continues to lower however appears to bounce again after 375k iterations. The bounce again means that the mannequin has begun to overfit.
The bigger DFN-2B dataset begins with the next validation loss and reduces on the similar price because the earlier however doesn’t recommend overfitting. A mixed dataset (DFN-2B+) performs the perfect by surpassing the IN-1k dataset in validation loss and doesn’t overfit.
Conclusions
The experiments’ observations concluded that the proposed fashions scale effectively by way of efficiency. Coaching with a bigger dataset (massive pictures processed) carried out higher with rising iterations. The identical was noticed with rising mannequin capability (rising the variety of parameters).
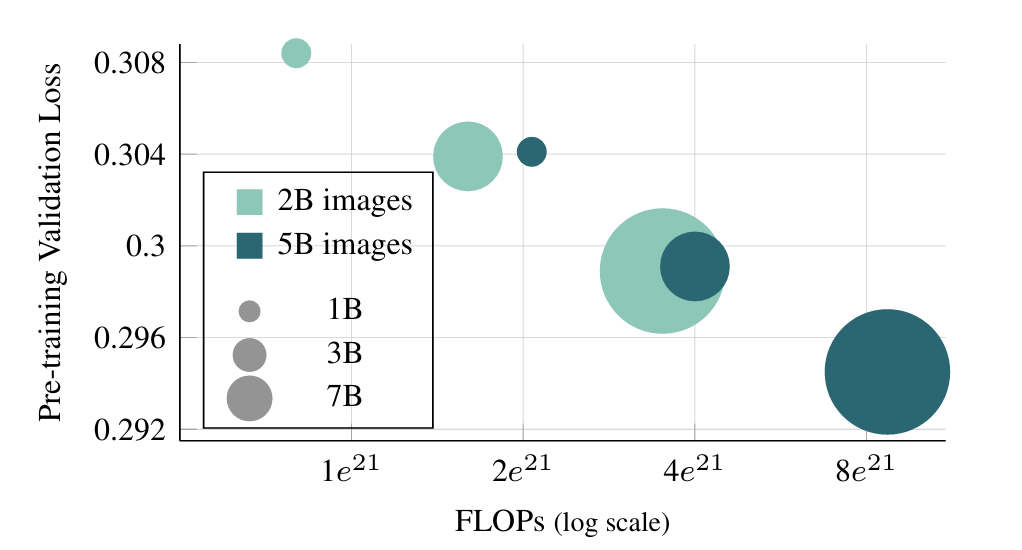
General, the fashions displayed related traits as seen in Giant Language Fashions, the place bigger fashions show higher loss after quite a few iterations. Apparently sufficient, lower-capacity fashions educated for an extended schedule obtain comparable validation loss in comparison with higher-capacity fashions educated for a shorter schedule whereas utilizing the same quantity of FLOPs.
Efficiency Comparability on Downstream Duties
The AIM fashions had been in contrast in opposition to a variety of different generative and autoregressive fashions on a number of downstream duties. The outcomes are summarised within the desk beneath:
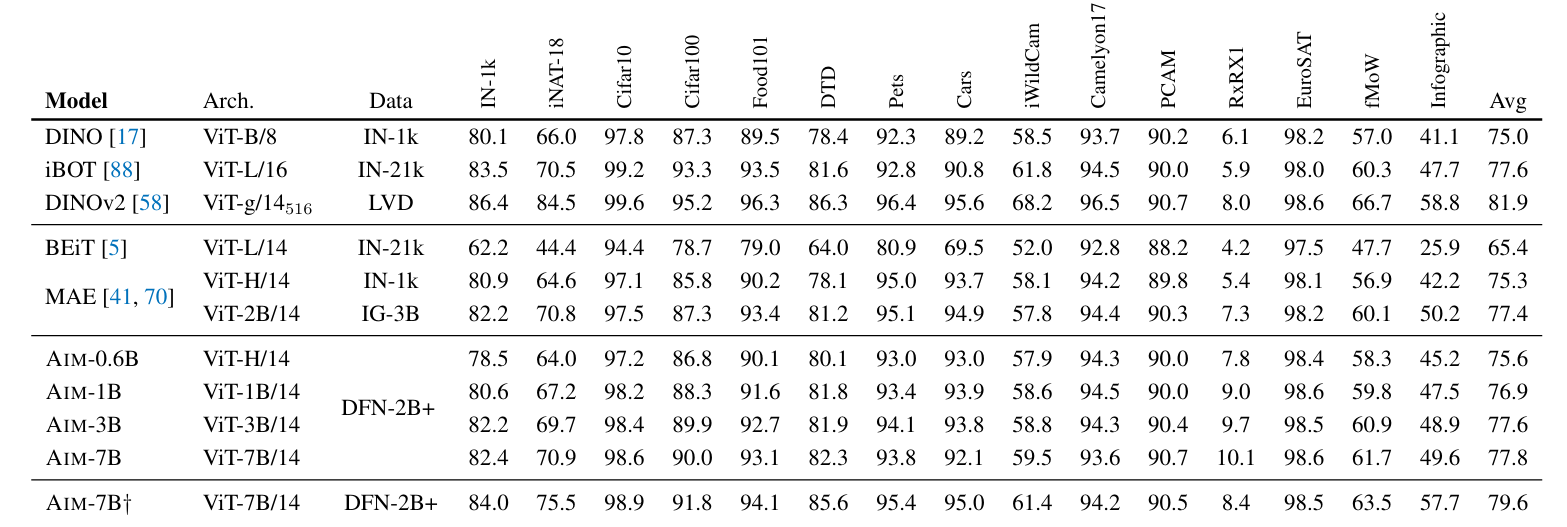
AIM outperforms most generative diffusion fashions resembling BEiT and MAE for a similar capability and even bigger. It achieves related efficiency in comparison with the joint embedding fashions like DINO and iBOT and falls simply behind the far more complicated DINOv2.
General, the AIM household supplies the right mixture of efficiency, accuracy, and scalability.
Abstract
The Autoregressive Picture Fashions (AIMs), launched by Apple analysis, show state-of-the-art scaling capabilities. The fashions are unfold throughout completely different parameter counts and every of them presents a steady pre-training expertise all through.
These AIM fashions use a transformer structure mixed with an MLP head for pretraining and are educated on a cleaned-up dataset from the Knowledge Filtering Networks (DFN). The experimentation section examined completely different mixtures of mannequin sizes and take a look at units in opposition to completely different subsets of the primary information. In every situation, the pre-training efficiency scaled fairly linearly with rising mannequin and information dimension.
The AIM fashions have distinctive scaling capabilities as noticed from their validation losses. The fashions additionally show aggressive efficiency in opposition to related picture era and joint embedding fashions and strike the right steadiness between pace and accuracy.
")