

In at the moment’s digital world, Synthetic Intelligence (AI) and Machine studying (ML) fashions are used all over the place, from face detection in digital gadgets to real-time language translation. Environment friendly, fast, and cost-effective studying processes are essential for scaling these fashions.
Switch Studying is a key approach applied by researchers and ML scientists to reinforce effectivity and scale back prices in Deep studying and Pure Language Processing.
On this weblog, we’ll discover the idea of switch studying, the way it technically works, and supply a step-by-step information to implementing it in Python.
About us: Viso Suite is our end-to-end pc imaginative and prescient infrastructure for enterprises. The highly effective resolution permits groups to develop, deploy, handle, and safe pc imaginative and prescient functions in a single place. Ebook a demo to be taught extra.
What’s Switch Studying?
Because the identify suggests, this system entails transferring the learnings of 1 skilled machine studying mannequin to a different, within the type of neural community weights. This supplies a big edge to companies as they don’t want to coach a mannequin from scratch. For instance, to coach a mannequin to translate German film subtitles to English, we have now to normally practice it with hundreds of German and English textual content corpora, in order that it may possibly perceive and translate.
However, there are open supply fashions like German-BERT which can be already skilled on large information corpora, with many parameters. Via switch studying, illustration studying of German-BERT is utilized and extra subtitle information is offered. Allow us to perceive how this works.
To grasp how switch studying works, it’s important to know the structure of Deep Neural Networks. Neural Networks are essentially the most extensively used algorithm to construct ML fashions for a lot of superior duties, as they’ve proven larger efficiency accuracy than conventional algorithms.
Understanding Neural Networks
Any neural community structure consists of three fundamental components: the enter layer, a number of hidden layers, and the output.
The hidden layers have neurons, that are initialized with random weights at the start. Throughout coaching, we provide the enter variables to the enter layer. Then the layers of the neural community extract options, be taught information patterns, and replace their weights. On the finish of coaching, all models would have realized the weights and might make predictions.
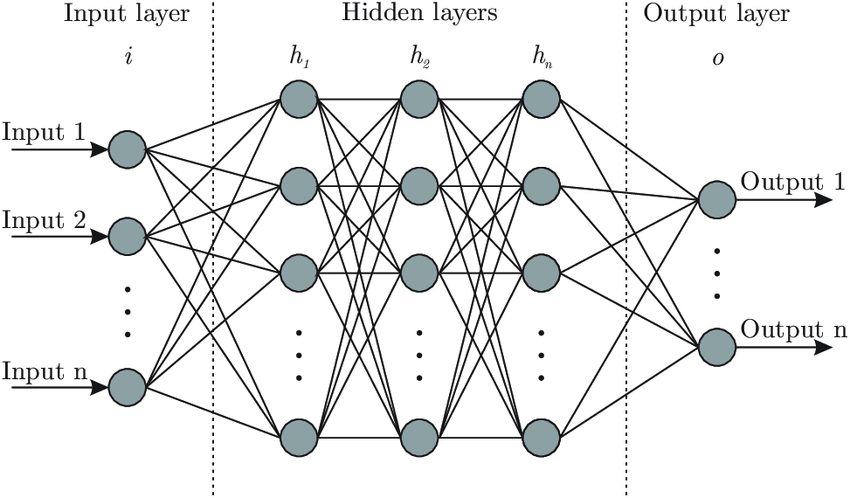
Switch Studying in Neural Networks
The primary hurdle in implementing neural networks is the lengthy coaching time and computational prices incurred. The method could be a lot faster if we may retain the realized weights of a mannequin (additionally known as ‘pre-trained weights’), and re-use them for the same use case. That is the place switch studying comes into play.
In switch studying, we initialize the neurons with pre-trained weights, somewhat than random ones. The bottom mannequin leveraged for the realized weights is known as the ‘Pre-trained Mannequin’, and is normally skilled with heavy parameters.
There are a lot of such pre-trained fashions obtainable in open-source, and in addition some that require paid subscriptions. Some widespread free-to-use pre-trained fashions embrace BERT, ResNet, YOLO and so forth.
Why do we’d like switch studying?
Switch studying can assist resolve many challenges confronted throughout real-time ML mannequin constructing. A few of them embrace:
- Diminished want for information: A number of man-hours wanted to gather high-quality information might be saved by switch studying. We will additionally keep away from the efforts required in annotation to create labels manually. We will take a pre-trained mannequin and fine-tune it on small datasets.
- Area Adaption: Contemplate a website in a distinct segment space, for instance analyzing monetary studies and summarizing the important thing factors. If we practice the mannequin from scratch, it might take loads of time for it to be taught the fundamentals. With a pre-trained mannequin, this may already be taken care of. We will make the most of this time to finetune it on domain-specific phrases (KPIs and so forth.).
- Decrease Prices & Sources: Each ML workforce desires to construct an reasonably priced and dependable mannequin. Groups can’t afford to burn money on computational sources for all of the duties. With switch studying, the reminiscence and GPU clusters wanted are decreased, lowering storage, and cloud computation prices.
- Keep away from Overfitting with restricted information: In lots of domains like credit score threat, and healthcare, information is commonly restricted for small-scale corporations or startups. In such instances, the mannequin typically overfits the coaching information pattern. This results in poor generalization in the direction of unseen information. This drawback might be mitigated by leveraging switch studying.
- Helps Incremental Studying: The mannequin efficiency might be iteratively improved by fine-tuning it to cowl the gaps. This may be very useful when the mannequin is working in actual time. As a result of, the info distributions could change over intervals, or as a consequence of seasonality spikes, and so forth.
- Promotes R&D: Switch studying accelerates R&D in ML because it supplies a base to start out. Researchers can give attention to particular points of an issue with out restarting from scratch. Examples embrace LLMs to offer information summaries with various views, and so forth.
How does switch studying work?
Allow us to perceive how switch studying works with a sensible instance. Contemplate a state of affairs through which we’re analyzing visitors surveillance, and wish to discover out which automobiles are the commonest. For this, we would want a deep studying mannequin that may classify a given enter picture right into a class of auto.
The car classes may very well be ‘Sedan’, ‘SUV’, ‘Truck’, ”Two-wheeler’, ‘Industrial vans’, and so forth. Now, let’s see find out how to construct a mannequin for this rapidly utilizing switch studying.
Step 1: Select a Pre-trained Mannequin
First, we select the bottom mannequin, whose pre-trained weights will likely be leveraged. There are a lot of open-source and paid choices obtainable for pre-trained fashions. Huggingface is a good platform to search out open-source fashions and OpenAI is among the finest paid choices.
The bottom mannequin ought to be skilled on the identical information kind as the present dataset. If we’re working with pictures, then we have to search for a mannequin skilled on many pictures, like ResNet or VGG.
We will select a language mannequin like BERT that may parse human textual content to construct an NLP mannequin equivalent to a textual content abstract. Subsequent, we have to search for fashions which can be skilled for related goals as the present activity. For instance, when you have a text-based sentiment classification activity at hand, selecting a mannequin skilled for textual content classification might be useful.
For our activity, we will likely be utilizing the VGG16 pre-trained mannequin. VGG16 has a CNN (Convolutional Neural Community) primarily based structure that has 16 layers. It’s skilled on the “ImageNet” dataset, which has a number of pictures in all classes like birds, fruits, automobiles, animals, and so forth. Since it’s skilled on an enormous dataset, it may possibly rapidly decide up the preliminary low-level characteristic representations of an enter picture like edges, shapes, and so forth.

Step 2: Pre-process your fine-tuning information
The bottom mannequin (pre-trained mannequin) is coded to just accept inputs in a particular format, relying upon the structure. The fine-tuning dataset must be transformed into the identical format in order that it’s suitable. For instance, language fashions normally take enter textual content within the type of tokens or vector embeddings. Whereas, picture recognition fashions settle for inputs within the format of pixels or Pytorch tensors.
For our activity, VGG16 requires enter pictures within the format of 224 x 224 pixels. So, we resize the pictures in our customized coaching information uniformly. Let’s additionally normalize the pictures, both to a regular 0–1 vary or utilizing imply and variance. This may assist in offering higher stability throughout mannequin coaching.
Knowledge augmentation strategies can be utilized to extend the fine-tuning information dimension or add extra variation to the pattern. A couple of widespread strategies for pictures embrace creating crop variations or performing flips and rotations. Notice that pre-processing is the stage the place we are able to make sure the mannequin will likely be sturdy after coaching, by cleansing up noise and guaranteeing variety within the pattern.
Step 3: Adapting the mannequin
Subsequent, we have to practice our customized dataset on prime of the bottom mannequin. There are two methods to strategy this: Characteristic extraction and Tremendous-tuning.
Characteristic extraction: On this strategy, we take the pre-trained mannequin with none adjustments and use it as a characteristic extractor. The pre-trained mannequin will extract the options from enter primarily based on its realized weights. Then, we construct a brand new classification mannequin, the place we offer these extracted options as enter. It’s a cost-effective methodology, as we don’t make any adjustments within the layers of the pre-trained mannequin.
Tremendous-tuning: On this methodology, together with the extra classifier layer on prime, we additionally re-train just a few higher layers of the bottom mannequin. The weights are frozen on the deep layers in order that realized options are usually not misplaced. Tremendous-tuning will present higher efficiency accuracy, because it will get skilled on the customized information.
In instances the place the area information has its particular nuances like medical pictures and monetary threat evaluation, fine-tuning is the higher selection. The draw back of fine-tuning is comparatively larger prices than characteristic extraction from pre-trained fashions.
We will select one amongst these approaches primarily based on some important components: area necessities and sensitivity degree of duties, affordability, and availability of ample information for fine-tuning.
For our activity of auto picture classification, we are able to go together with the characteristic extraction methodology as VGG16 is already uncovered to pictures of automobiles and different automobiles. Allow us to freeze the weights of all pre-trained layers in VGG16. These layers will extract options from the enter pictures we offer.
Step 4: Prepare on customized information & Consider
Primarily based on the selection within the earlier step, new information must be skilled accordingly. We will fine-tune the parameters like the training charge and batch dimension of the brand new classifier layer to get the perfect outcomes. A excessive studying charge may typically result in overfitting, whereas a low studying charge will waste sources.
We additionally must outline the loss perform that finest represents the duty at hand. Throughout coaching, the target of the mannequin is to reduce the loss perform. There are additionally completely different strategies to optimize the loss perform, like Stochastic Gradient descent, RMSProp (Root Imply Sq. Propagation), and Adam.
As soon as coaching is full, the mannequin might be evaluated on a set of unseen take a look at pictures. If there’s any repetition within the coaching and take a look at pattern, then the mannequin won’t generalize properly.
As our activity is a picture classification activity, we are able to go together with cross-entropy because the loss perform. It’s a widespread selection in multi-class classification initiatives. We will select the Adam optimizer (Adaptive Second Estimation), because it provides higher regularization. We will additionally create a confusion matrix of the take a look at information outcomes to see how properly the mannequin classifies completely different car classes.
Implementing Switch Studying utilizing PyTorch
First, begin by importing the mandatory Python packages. PyTorch will likely be used for constructing and coaching the neural community, torch-vision will likely be used to load and preprocess the info, and numpy will likely be used for numerical operations.
# Import packages and modules import torch import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler import numpy as np import torchvision from torchvision import datasets, fashions, transforms import matplotlib.pyplot as plt import time import os
Subsequent, outline information transformations and cargo the dataset. We use transformations equivalent to resizing, cropping, and normalization. This part additionally entails splitting the dataset into coaching and validation units.
# Outline information transforms
data_transforms = {
'practice': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# Set information listing
data_dir="path/to/your/dataset"
# Load dataset
image_datasets = {x: datasets.ImageFolder(os.path.be part of(data_dir, x), data_transforms[x])
for x in ['train', 'val']}
# Create dataloaders
dataloaders = {x: torch.utils.information.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4)
for x in ['train', 'val']}
# Get dataset sizes
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].lessons
Subsequent, we have to load the pre-trained VGG16 mannequin from the torch-vision fashions. We freeze the parameters of the pre-trained layers and modify the ultimate totally linked layer to match the variety of lessons in our dataset.
# Loading the pre-trained base mannequin
model_ft = fashions.vgg16(pretrained=True)
# Freeze parameters of pre-trained layers
for param in model_ft.parameters():
param.requires_grad = False
# Modify the classifier
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, len(class_names))
# Outline loss perform and optimizer
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by an element of 0.1 each 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
Right here’s the fundamental framework to coach the mannequin utilizing a loss perform, optimizer, and scheduler. Adjustments might be made as per necessities.
def train_model(mannequin, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = mannequin.state_dict()
best_acc = 0.0
for epoch in vary(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Every epoch has a coaching and validation section
for section in ['train', 'val']:
if section == 'practice':
mannequin.practice() # Set mannequin to coaching mode
else:
mannequin.eval() # Set mannequin to judge mode
running_loss = 0.0
running_corrects = 0
# Iterate over information.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(machine)
labels = labels.to(machine)
# Zero the parameter gradients
optimizer.zero_grad()
# Ahead cross
with torch.set_grad_enabled(section == 'practice'):
outputs = mannequin(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# Backward + optimize provided that in coaching section
if section == 'practice':
loss.backward()
optimizer.step()
# Statistics
running_loss += loss.merchandise() * inputs.dimension(0)
running_corrects += torch.sum(preds == labels.information)
if section == 'practice':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
section, epoch_loss, epoch_acc))
# Deep copy the mannequin
if section == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = mannequin.state_dict()
print()
time_elapsed = time.time() - since
print('Coaching full in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Finest val Acc: {:4f}'.format(best_acc))
# Load finest mannequin weights
mannequin.load_state_dict(best_model_wts)
return mannequin
# Prepare the mannequin
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25)
After this, you’ll be able to calculate metrics like F1 rating or confusion matrix to judge your mannequin. Make sure that to exchange 'path/to/your/dataset' with the precise path to your dataset. Additionally, you could want to regulate parameters equivalent to batch dimension, studying charge, and variety of epochs primarily based in your particular coaching dataset and {hardware} capabilities.
Sensible Purposes of Switch Studying

- Medical Analysis: We will construct diagnostic fashions even with small quantities of labeled medical information utilizing the pre-trained fashions on medical pictures.
- Wide selection of Chatbots: With pre-trained language fashions like BERT, and GPT, any enterprise can customise it to their wants. We will construct chatbots fine-tuned for taking appointments in hospitals or answering order queries on an e-commerce web site and so forth. The time taken to develop and current these chatbots to market has decreased with switch studying.
- Monetary Forecasting: Switch studying optimizes monetary forecasting fashions by leveraging pre-trained neural networks skilled on related financial information. This strategy accelerates mannequin convergence and enhances accuracy.
- Makes use of in NLP: NLP duties profit massively from switch studying. A mannequin skilled for sentiment evaluation on social media posts might be tailored to investigate buyer opinions, although the language used may be completely different.
Conclusion
Total, switch studying reveals loads of promise within the fields of deep studying and NLP. However, we also needs to take into account the prevailing limitations. The mannequin chosen could be taught some biases from the supply information of the pre-trained mannequin.
ML groups must examine for potential biases and take away them earlier than implementation. The workforce ought to constantly monitor the mannequin or place alert techniques to catch any information distribution drifts.
To discover extra concerning the world of pc imaginative and prescient and several types of networks, take a look at the next blogs:
")