

On this article, we are going to discover the second model of StyleGAN’s fashions from the paper Analyzing and Enhancing the Picture High quality of StyleGAN, which is clearly an enchancment over StyleGAN from the prior paper A Fashion-Based mostly Generator Structure for Generative Adversarial Networks. StyleGAN relies on ProGAN from the paper Progressive Rising of GANs for Improved High quality, Stability, and Variation. All three papers are from the identical authors from NVIDIA AI. We are going to undergo the StyleGAN2 challenge, see its objectives, the loss operate, and outcomes, break down its parts, and perceive every one. If you wish to see the implementation of it from scratch, take a look at this weblog, the place I replicate the unique paper as shut as attainable, and make an implementation clear, easy, and readable utilizing PyTorch.
StyleGAN2 Overview
On this part, we are going to go over StyleGAN2 motivation and get an introduction to its enchancment over StyleGAN.
StyleGAN2 motivation
StyleGAN2 is basically motivated by resolving the artifacts launched in StyleGAN1 that can be utilized to establish pictures generated from the StyleGAN structure. Try this web site whichfaceisreal which has a protracted checklist of those completely different artifacts that you should utilize to inform if a picture was created by StyleGAN or it was an actual picture.
Introduction of StyleGAN2 enchancment over StyleGAN
StyleGAN is a really sturdy GAN architectures: it generates actually extremely lifelike pictures with excessive decision, the primary parts it’s the usage of adaptive occasion normalization (AdaIN), a mapping community from the latent vector Z into W, and the progressive rising of going from low-resolution pictures to high-resolution pictures. StyleGAN2 restricts the usage of adaptive occasion normalization, will get away from progressive rising to eliminate the artifacts launched in StyleGAN1, and introduces a perceptual path size normalization time period within the loss operate to enhance the latent area interpolation capacity which describes the modifications within the generated pictures when altering the latent vector Z and introduces a deep defeat detection algorithm to challenge a generated pictures again into latent area.
StyleGAN artifacts
The authors of StyleGAN2 establish two causes for the artifacts launched in StyleGAN1 and describe modifications in structure and coaching strategies that get rid of them.
The primary trigger
Within the determine under you may see a gif extracted from the video launched with the paper that reveals examples of the droplet artifacts; the authors establish the reason for these artifacts to the best way that the adaptive occasion normalization layer is structured. It’s attention-grabbing once they see that the artifacts begin from 64 by 64 decision scale after which persist all the best way as much as 1024 by 1024 scale.
The authors of StyleGAN2 limit the usage of adaptive occasion normalization to eliminate the artifacts launched above. And so they truly obtain their objectives. We will see within the determine above the outcomes after the modifications in structure and coaching strategies that get rid of the artifacts.

The second trigger
The authors observed that, as they scale up the photographs that stroll alongside the latent area, some form of options akin to mounts and eyes (if we generate faces) are form of mounted in place. They attribute this to the construction of the progressive rising, and having these intermediate scales and desires intermediate low-resolution maps which have for use to provide pictures that idiot a discriminator. Within the determine under, we are able to see some examples of that.

The authors of StyleGAN2 get away from progressive rising to eliminate the artifacts launched above. And once more, they obtain their objectives.

AdaIN revisited
The authors of StyleGAN2 take away the adaptive occasion normalization operator and change it with the burden modulation and demodulation step. The concept is that scaling the parameters through the use of Si from the information normalization from the intermediate noise vector (w within the determine under refers to weights not intermediate latent area, we’re sticking to the identical notation because the paper.), the place i is the enter channel, j is the output channel, and ok is the kernel index.
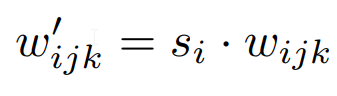
After which we demodulate it to imagine that the options have unit variance.
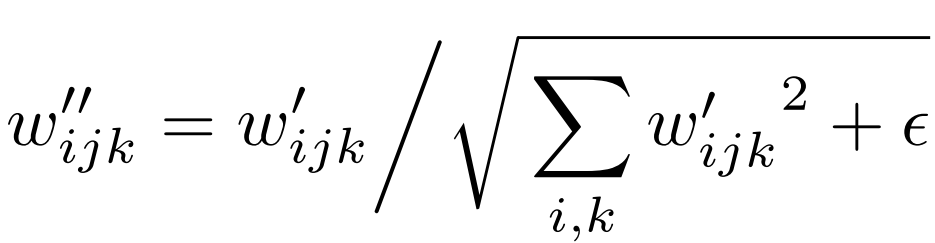
Perceptual path size regularization
The subsequent technical change the authors make to StaleGAN2 is so as to add Perceptual path size regularization to the loss operate of the generator to not have too dramatic modifications within the generated picture once we change within the latent area Z. If we barely change the latent vector Z, then we would like it to be a clean change within the semantics of the generated picture – somewhat than having a totally completely different picture generated with respect to a small change within the latent area Z.
The authors argue for the usage of the perceptual path size picture high quality metric in comparison with the FID rating or precision and recall. Within the determine under, we are able to see some examples of the underside 10% on the left and the highest 90% on the correct of the instances the place low perceptual path size scores are extremely correlated with our human judgment of the standard of the photographs.

Within the appendix of the paper, the authors additional present grids of pictures which have related FID scores however completely different perceptual path size scores, and you’ll see the grids within the determine under that the teams of pictures with the decrease perceptual path size scores typically are higher pictures.

To implement perceptual path size regularization the authors calculate the Jacobian matrix Jw which is form of seeing the partial derivatives of the output with respect to the small modifications within the latent vector that produces the photographs.
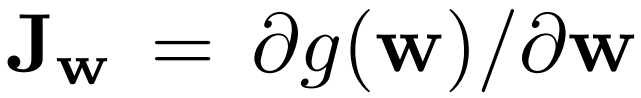
Then they use the Jacobian matrix Jw, multiply it by a random picture Y, and the picture Y is randomly sampled in every iteration to keep away from having some form of a spatial location dependency launched by Y. They then take the L2 norm of this sort of matrix, and so they subtract it by an exponential transferring common, and, lastly, they sq. it.

They do that as a way to regulate the perceptual path size and ensure that the modifications in latent vector Z don’t result in dramatic modifications within the generated pictures.
Lazy regulation is a really computationally heavy course of, so the authors add it within the loss operate each 16 steps.
Progressive rising revisited
The final change in StyleGAN2 described within the paper is to get rid of the progressive rising. In progressive rising, when the community completed producing pictures with decision of some arbitrary measurement like 16 by 16, they add a brand new layer to generate a double measurement pictures decision. They up pattern the beforehand generated picture as much as 32 by 32, after which they use the components under [(1−α)×UpsampledLayer+(α)×ConvLayer] to get the upscaled picture.
The issue with progressive rising is there are lots of hyperparameters looking out with respect to α that goes with respect to every scale (4×4, 8×8, 16×16, and so forth). Moreover, this simply complicates coaching rather a lot, and it is not a enjoyable factor to implement.
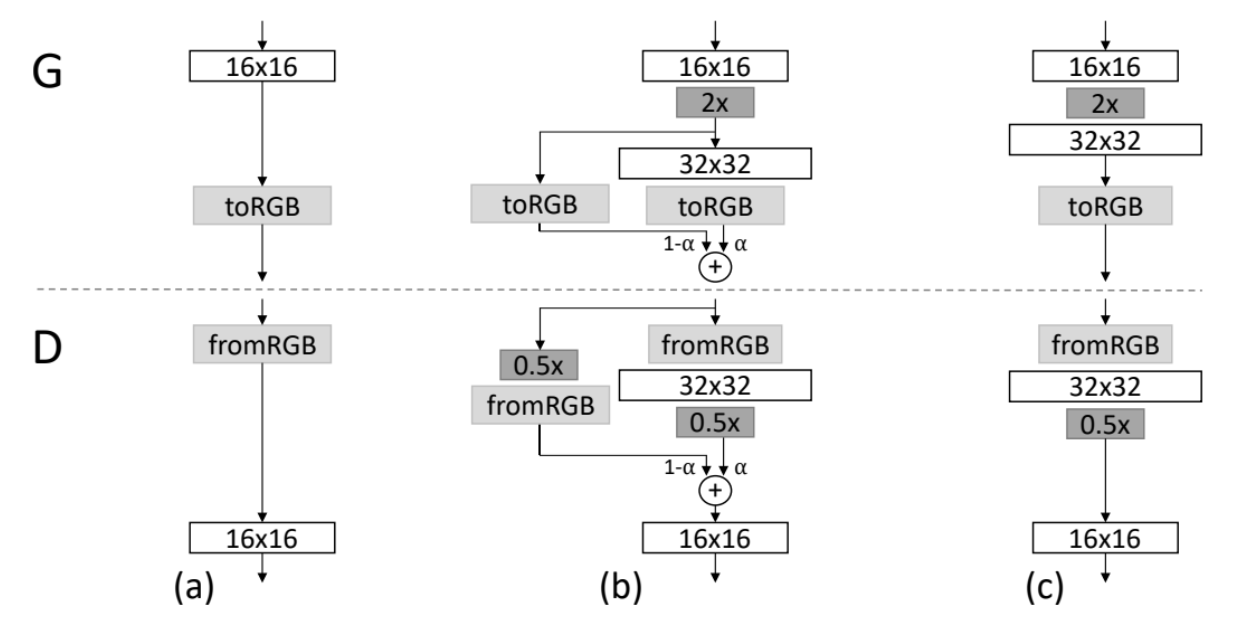
The authors of StyleGAN2 had been impressed by MSG-GAN, from the paper MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks, to provide you with two different architectures to get away from progressive rising.
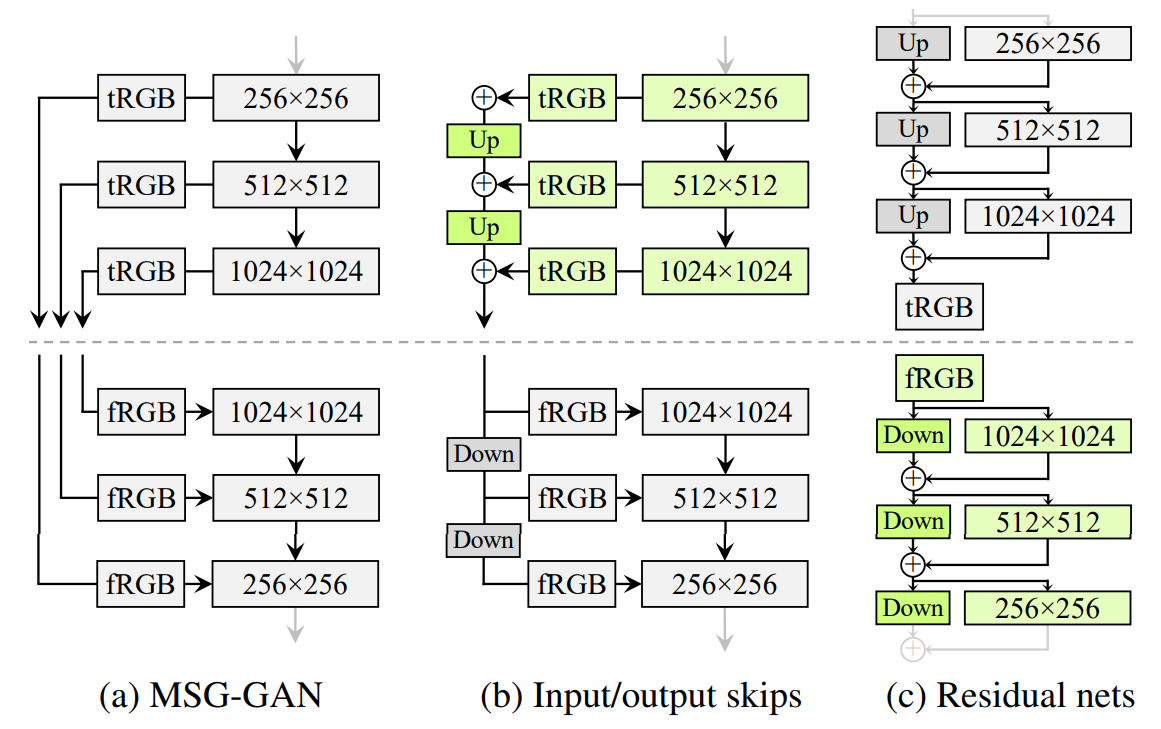
- In MSG-GAN they use intermediate function maps within the generator, after which supplied that as further options to the discriminator
- In enter/output skips they simplify the MSG-GAN structure by upsampling and summing the contributions of RGB outputs equivalent to completely different resolutions. Within the discriminator, they equally present the downsampled picture to every decision block of the discriminator. They use bilinear filtering in all up-and-down sampling operations
- In Residual nets, they additional modify the structure to make use of residual connections
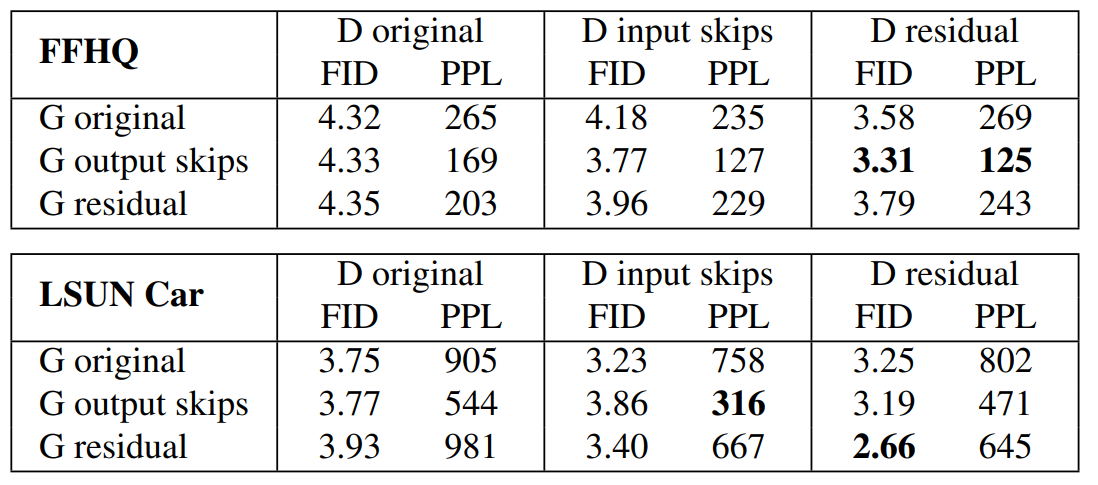
Within the determine above you may see the comparability of generator and discriminator architectures with out progressive rising that the authors made. It reveals that there is actually not a lot of a distinction between the skip and residual architectures within the ensuing picture high quality.
Projection of pictures into latent area
One other attention-grabbing factor the authors of StyleGAN2 current within the paper is a deep pretend detection algorithm by projecting this picture again into the latent area. The concept is we take as enter a picture that whether it is pretend we are able to discover a latent vector that produces the identical picture, and whether it is actual we can’t discover any latent vector that produces the identical picture.
Outcomes

The pictures generated by StyleGAN2 don’t have any artifacts like those generated by STyleGAN1 and that makes them extra lifelike in a method that you simply could not differentiate between them and the actual ones.
Conclusion
On this article, we undergo the StyleGAN2 paper, which is an enchancment over StyleGAN1, the important thing modifications are restructuring the adaptive occasion normalization utilizing the burden demodulation method, changing the progressive rising with the skip connection structure/residual structure, after which utilizing the perceptual path size normalization. All of that enhance the standard of the generated pictures and get away from the artifacts launched in StyleGAN1.
Hopefully, it is possible for you to to observe the entire steps and get a very good understanding of StyleGAN2, and you’re able to sort out the implementation, you could find it on this article the place I make a clear, easy, and readable implementation of it to generate some vogue.
")