

Think about coaching a mannequin on uncooked knowledge with out cleansing, reworking, or optimizing it.
The outcomes?
Poor predictions, wasted assets, and suboptimal efficiency. Characteristic engineering is the artwork of extracting probably the most related insights from knowledge, guaranteeing that machine studying fashions work effectively.
Whether or not you’re coping with structured knowledge, textual content, or pictures, mastering function engineering is usually a game-changer. This information covers the simplest strategies and greatest practices that will help you construct high-performance fashions.
What’s Characteristic Engineering?
Characteristic engineering is the artwork of changing uncooked knowledge into helpful enter variables (options) that enhance the efficiency of machine studying fashions. It helps in selecting probably the most helpful options to boost a mannequin’s capability to study patterns & make good predictions.
Characteristic engineering encompasses strategies like function scaling, encoding categorical variables, function choice, and constructing interplay phrases.
Why is Characteristic Engineering Essential for Predictive Modeling?
Characteristic engineering is without doubt one of the most crucial steps in machine studying. Even probably the most superior algorithms can fail if they’re educated on poorly designed options. Right here’s why it issues:
1. Improves Mannequin Accuracy
A well-engineered function set permits a mannequin to seize patterns extra successfully, resulting in greater accuracy. For instance, changing a date column into “day of the week” or “vacation vs. non-holiday” can enhance gross sales forecasting fashions.
2. Reduces Overfitting and Underfitting
By eradicating irrelevant or extremely correlated options, function engineering prevents the mannequin from memorizing noise (overfitting) and ensures it generalizes nicely on unseen knowledge.
3. Enhances Mannequin Interpretability
Options that align with area data make the mannequin’s choices extra explainable. As an illustration, in fraud detection, a function like “variety of transactions per hour” is extra informative than uncooked timestamps.
4. Boosts Coaching Effectivity
Lowering the variety of pointless options decreases computational complexity, making coaching sooner and extra environment friendly.
5. Handles Noisy and Lacking Information
Uncooked knowledge is usually incomplete or incorporates outliers. Characteristic engineering helps clear and construction this knowledge, guaranteeing higher studying outcomes.
Key Strategies of Characteristic Engineering
1. Characteristic Choice
Deciding on probably the most related options whereas eliminating redundant, irrelevant, or extremely correlated variables helps enhance mannequin effectivity and accuracy.
Methods:
- Filter Strategies: Makes use of statistical strategies like correlation, variance threshold, or mutual data to pick out necessary options.
- Wrapper Strategies: Makes use of iterative strategies like Recursive Characteristic Elimination (RFE) and stepwise choice.
- Embedded Strategies: Characteristic choice is constructed into the algorithm, resembling Lasso Regression (L1 regularization) or resolution tree-based fashions.
Instance: Eradicating extremely correlated options like “Complete Gross sales” and “Common Month-to-month Gross sales” if one will be derived from the opposite.
2. Characteristic Transformation
Transforms uncooked knowledge to enhance mannequin studying by making it extra interpretable or lowering skewness.
Methods:
- Normalization (Min-Max Scaling): Rescales values between 0 and 1. Helpful for distance-based fashions like k-NN.
- Standardization (Z-score Scaling): Transforms knowledge to have a imply of 0 and normal deviation of 1. Works nicely for gradient-based fashions like logistic regression.
- Log Transformation: Converts skewed knowledge into a traditional distribution.
- Energy Transformation (Field-Cox, Yeo-Johnson): Used to stabilize variance and make knowledge extra normal-like.
Instance: Scaling buyer earnings earlier than utilizing it in a mannequin to stop high-value dominance.
3. Characteristic Encoding
Categorical options have to be transformed into numerical values for machine studying fashions to course of.
Methods:
- One-Sizzling Encoding (OHE): Creates binary columns for every class (appropriate for low-cardinality categorical variables).
- Label Encoding: Assigns numerical values to classes (helpful for ordinal classes like “low,” “medium,” “excessive”).
- Goal Encoding: Replaces classes with the imply goal worth (generally utilized in regression fashions).
- Frequency Encoding: Converts classes into their prevalence frequency within the dataset.
Instance: Changing “Metropolis” into a number of binary columns utilizing one-hot encoding:
| Metropolis | New York | San Francisco | Chicago |
| NY | 1 | 0 | 0 |
| SF | 0 | 1 | 0 |
4. Characteristic Creation (Derived Options)
Characteristic creation includes establishing new options from current ones to offer further insights and enhance mannequin efficiency. Effectively-crafted options can seize hidden relationships in knowledge, making patterns extra evident to machine studying fashions.
Methods:
- Polynomial Options: Helpful for fashions that must seize non-linear relationships between variables.
- Instance: If a mannequin struggles with a linear relationship, including polynomial phrases like x², x³, or interplay phrases (x1 * x2) can enhance efficiency.
- Use Case: Predicting home costs primarily based on options like sq. footage and variety of rooms. As a substitute of simply utilizing sq. footage, a mannequin may benefit from an interplay time period like square_footage * number_of_rooms.
- Binning (Discretization): Converts steady variables into categorical bins to simplify the connection.
- Instance: As a substitute of utilizing uncooked age values (22, 34, 45), we are able to group them into bins:
- Younger (18-30)
- Center-aged (31-50)
- Senior (51+)
- Use Case: Credit score danger modeling, the place totally different age teams have totally different danger ranges.
- Instance: As a substitute of utilizing uncooked age values (22, 34, 45), we are able to group them into bins:
- Ratio Options: Creating ratios between two associated numerical values to normalize the affect of scale.
- Instance: As a substitute of utilizing earnings and mortgage quantity individually, use Revenue-to-Mortgage Ratio = Revenue / Mortgage Quantity to standardize comparisons throughout totally different earnings ranges.
- Use Case: Mortgage default prediction, the place people with a better debt-to-income ratio usually tend to default.
- Time-based Options: Extracts significant insights from timestamps, resembling:
- Hour of the day (helps in visitors evaluation)
- Day of the week (helpful for gross sales forecasting)
- Season (necessary for retail and tourism industries)
- Use Case: Predicting e-commerce gross sales by analyzing traits primarily based on weekdays vs. weekends.
Instance:
| Timestamp | Hour | Day of Week | Month | Season |
| 2024-02-15 14:30 | 14 | Thursday | 2 | Winter |
| 2024-06-10 08:15 | 8 | Monday | 6 | Summer time |
5. Dealing with Lacking Information
Lacking knowledge is widespread in real-world datasets and might negatively affect mannequin efficiency if not dealt with correctly. As a substitute of merely dropping lacking values, function engineering strategies assist retain useful data whereas minimizing bias.
Methods:
- Imply/Median/Mode Imputation:
- Fills lacking values with the imply (for numerical knowledge) or mode (for categorical knowledge).
- Instance: Filling lacking wage values with the median wage of the dataset to stop skewing the distribution.
- Ahead or Backward Fill (Time-Sequence Information):
- Ahead fill: Makes use of the final identified worth to fill lacking entries.
- Backward fill: Makes use of the subsequent identified worth to fill lacking entries.
- Use Case: Inventory market knowledge the place lacking costs will be full of the day prior to this’s costs.
- Okay-Nearest Neighbors (KNN) Imputation:
- Makes use of related knowledge factors to estimate lacking values.
- Instance: If an individual’s earnings is lacking, KNN can predict it primarily based on folks with related job roles, schooling ranges, and places.
- Indicator Variable for Missingness:
- Creates a binary column (1 = Lacking, 0 = Current) to retain lacking knowledge patterns.
- Use Case: Detecting fraudulent transactions the place lacking values themselves might point out suspicious exercise.
Instance:
| Buyer ID | Age | Wage | Wage Lacking Indicator |
| 101 | 35 | 50,000 | 0 |
| 102 | 42 | NaN | 1 |
| 103 | 29 | 40,000 | 0 |
Characteristic extraction includes deriving new, significant representations from complicated knowledge codecs like textual content, pictures, and time-series. That is particularly helpful in high-dimensional datasets.
Methods:
- Textual content Options: Converts textual knowledge into numerical kind for machine studying fashions.
- Bag of Phrases (BoW): Represents textual content as phrase frequencies in a matrix.
- TF-IDF (Time period Frequency-Inverse Doc Frequency): Provides significance to phrases primarily based on their frequency in a doc vs. total dataset.
- Phrase Embeddings (Word2Vec, GloVe, BERT): Captures semantic that means of phrases.
- Use Case: Sentiment evaluation of buyer evaluations.
- Picture Options: Extract important patterns from pictures.
- Edge Detection: Identifies object boundaries in pictures (helpful in medical imaging).
- Histogram of Oriented Gradients (HOG): Utilized in object detection.
- CNN-primarily based Characteristic Extraction: Makes use of deep studying fashions like ResNet and VGG for computerized function studying.
- Use Case: Facial recognition, self-driving automobile object detection.
- Time-Sequence Options: Extract significant traits and seasonality from time-series knowledge.
- Rolling Averages: Easy out short-term fluctuations.
- Seasonal Decomposition: Separates development, seasonality, and residual parts.
- Autoregressive Options: Makes use of previous values as inputs for predictive fashions.
- Use Case: Forecasting electrical energy demand primarily based on historic consumption patterns.
- Dimensionality Discount (PCA, t-SNE, UMAP):
- PCA (Principal Element Evaluation) reduces high-dimensional knowledge whereas preserving variance.
- t-SNE and UMAP are helpful for visualizing clusters in massive datasets.
- Use Case: Lowering hundreds of buyer habits variables into a number of principal parts for clustering.
Instance:
For textual content evaluation, TF-IDF converts uncooked sentences into numerical kind:
| Sentence | “AI is reworking healthcare” | “AI is advancing analysis” |
| AI | 0.4 | 0.3 |
| reworking | 0.6 | 0.0 |
| analysis | 0.0 | 0.7 |
7. Dealing with Outliers
Outliers are excessive values that may distort a mannequin’s predictions. Figuring out and dealing with them correctly prevents skewed outcomes.
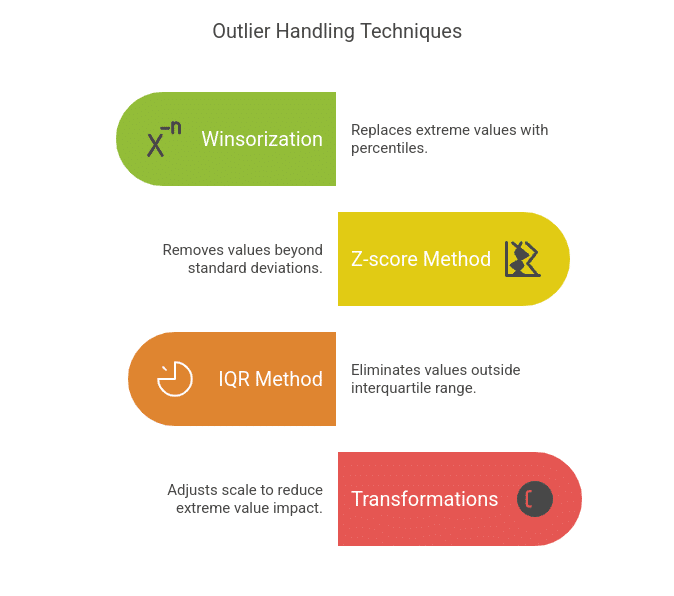
Methods:
- Winsorization: Replaces excessive values with a specified percentile (e.g., capping values on the fifth and ninety fifth percentile).
- Z-score Methodology: Removes values which can be greater than a sure variety of normal deviations from the imply (e.g., ±3σ).
- IQR (Interquartile Vary) Methodology: Removes values past 1.5 instances the interquartile vary (Q1 and Q3).
- Transformations (Log, Sq. Root): Reduces the affect of maximum values by adjusting scale.
Instance:
Detecting outliers in a wage dataset utilizing IQR:
| Worker | Wage | Outlier (IQR Methodology) |
| A | 50,000 | No |
| B | 52,000 | No |
| C | 200,000 | Sure |
8. Characteristic Interplay
Characteristic interplay helps seize relationships between variables that aren’t apparent of their uncooked kind.
Methods:
- Multiplication or Division of Options:
- Instance: As a substitute of utilizing “Weight” and “Top” individually, create BMI = Weight / Height².
- Polynomial Options:
- Instance: Including squared or cubic phrases for higher non-linear modelling.
- Clustering-Primarily based Options:
- Assign cluster labels utilizing k-means, which can be utilized as categorical inputs.
Instance:
Creating an “Engagement Rating” for a person primarily based on:
Engagement Rating = (Logins * Time Spent) / (1 + Bounce Charge).
By leveraging these function engineering strategies, you’ll be able to remodel uncooked knowledge into highly effective predictive inputs, finally bettering mannequin accuracy, effectivity, and interoperability.
Comparability: Good vs. Dangerous Characteristic Engineering
Information Preprocessing
Good Characteristic Engineering
Handles lacking values, removes outliers, and applies correct scaling.
Dangerous Characteristic Engineering
Ignores lacking values, consists of outliers, and fails to standardize.
Characteristic Choice
Good Characteristic Engineering
Makes use of correlation evaluation, significance scores, and area experience to choose options.
Dangerous Characteristic Engineering
Makes use of all options, even when some are redundant or irrelevant.
Characteristic Transformation
Good Characteristic Engineering
Normalizes, scales, and applies log transformations when mandatory.
Dangerous Characteristic Engineering
Makes use of uncooked knowledge with out processing, resulting in inconsistent mannequin habits.
Encoding Categorical Information
Good Characteristic Engineering
Makes use of correct encoding strategies like one-hot, goal, or frequency encoding.
Dangerous Characteristic Engineering
Assigns arbitrary numeric values to classes, deceptive the mannequin.
Characteristic Creation
Good Characteristic Engineering
Introduces significant new options (e.g., ratios, interactions, polynomial phrases).
Dangerous Characteristic Engineering
Provides random variables or duplicates current options.
Dealing with Time-based Information
Good Characteristic Engineering
Extracts helpful patterns (e.g., day of the week, development indicators).
Dangerous Characteristic Engineering
Leaves timestamps in uncooked format, making patterns tougher to study.
Mannequin Efficiency
Good Characteristic Engineering
Larger accuracy, generalizes nicely on new knowledge, interpretable outcomes.
Dangerous Characteristic Engineering
Poor accuracy, overfits coaching knowledge, fails in real-world eventualities.
How Does Good and Dangerous Characteristic Engineering Have an effect on Mannequin Efficiency?
Instance 1: Predicting Home Costs
- Good Characteristic Engineering: As a substitute of utilizing the uncooked “12 months Constructed” column, create a brand new function: “Home Age” (Present 12 months – 12 months Constructed). This supplies a clearer relationship with worth.
- Dangerous Characteristic Engineering: Retaining the “12 months Constructed” column as-is, forcing the mannequin to study complicated patterns as a substitute of specializing in a simple numerical relationship.
Instance 2: Credit score Card Fraud Detection
- Good Characteristic Engineering: Creating a brand new function “Variety of Transactions within the Final Hour” helps determine suspicious exercise.
- Dangerous Characteristic Engineering: Utilizing uncooked timestamps with none transformation, making it tough for the mannequin to detect time-based anomalies.
Instance 3: Buyer Churn Prediction
- Good Characteristic Engineering: Combining buyer interplay knowledge right into a “Month-to-month Exercise Rating” (e.g., logins, purchases, help queries).
- Dangerous Characteristic Engineering: Utilizing every interplay sort individually, making the dataset unnecessarily complicated and tougher for the mannequin to interpret.
Finest Practices in Characteristic Engineering
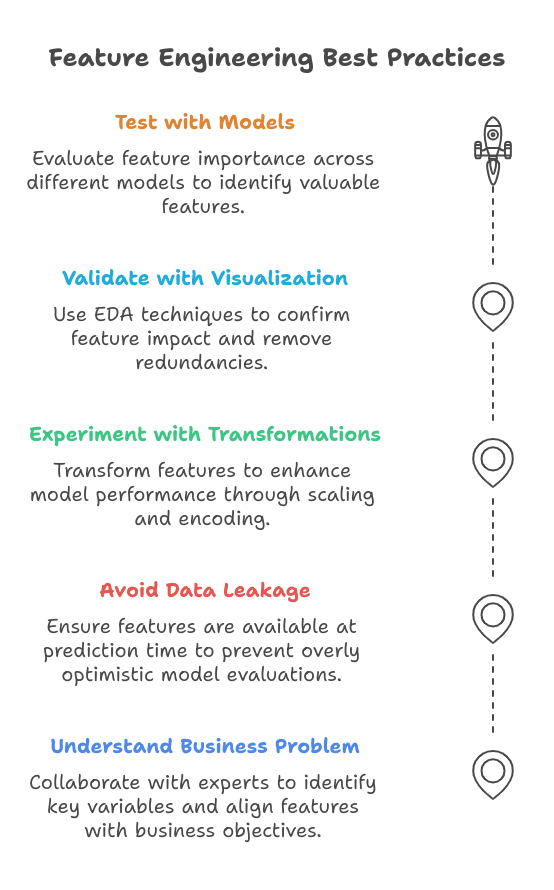
1. Understanding the Enterprise Downside Earlier than Deciding on Options
Earlier than making use of function engineering strategies, it’s essential to know the precise drawback the mannequin goals to resolve. Deciding on options with out contemplating the area context can result in irrelevant or deceptive inputs, lowering mannequin effectiveness.
Finest Practices:
- Collaborate with area consultants to determine key variables.
- Analyze historic traits and real-world constraints.
- Guarantee chosen options align with enterprise targets.
Instance:
For a mortgage default prediction mannequin, options like credit score rating, earnings stability, and previous mortgage compensation habits are extra useful than generic options like ZIP code.
2. Avoiding Information Leakage By Cautious Characteristic Choice
Information leakage happens when data from the coaching set is inadvertently included within the take a look at set, resulting in overly optimistic efficiency that doesn’t generalize nicely to real-world eventualities.
Finest Practices:
- Exclude options that wouldn’t be obtainable on the time of prediction.
- Keep away from utilizing future data in coaching knowledge.
- Be cautious with derived options primarily based on track variables.
Instance of Information Leakage:
Utilizing “complete purchases within the subsequent 3 months” as a function to foretell buyer churn. Since this data wouldn’t be obtainable on the prediction time, it might result in incorrect mannequin analysis.
Repair: Use previous buy habits (e.g., “variety of purchases within the final 6 months”) as a substitute.
3. Experimenting with Completely different Transformations and Encodings
Remodeling options into extra appropriate codecs can considerably improve mannequin efficiency. This consists of scaling numerical variables, encoding categorical variables, and making use of mathematical transformations.
Finest Practices:
- Scaling numerical variables (Min-Max Scaling, Standardization) to make sure consistency.
- Encoding categorical variables (One-Sizzling, Label Encoding, Goal Encoding) primarily based on knowledge distribution.
- Making use of transformations (Log, Sq. Root, Energy Rework) to normalize skewed knowledge.
Instance:
For a dataset with extremely skewed earnings knowledge:
- Uncooked Revenue Information: [10,000, 20,000, 50,000, 1,000,000] (skewed distribution)
- Log Transformation: [4, 4.3, 4.7, 6] (reduces skewness, bettering mannequin efficiency).
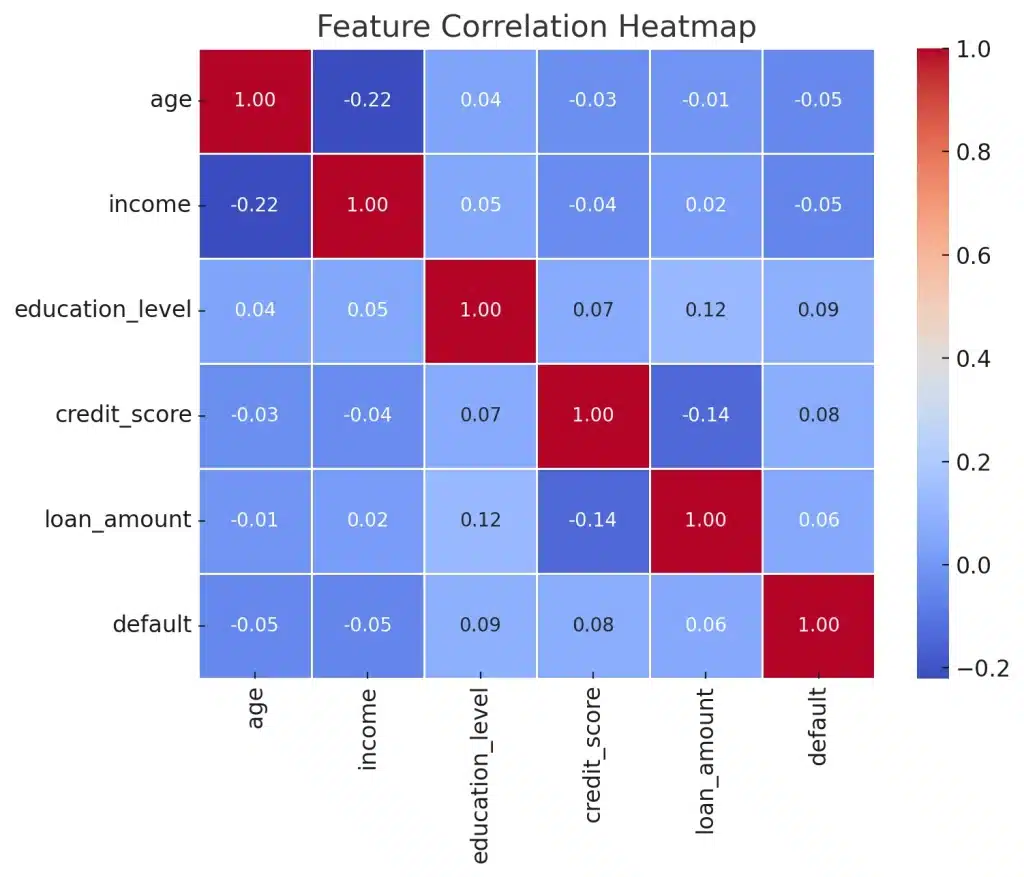
4. Validating Engineered Options Utilizing Visualization and Correlation Evaluation
Earlier than finalizing options, it’s important to validate their affect utilizing exploratory knowledge evaluation (EDA) strategies.
Finest Practices:
- Use histograms and field plots to examine function distributions.
- Use scatter plots and correlation heatmaps to determine relationships between variables.
- Take away extremely correlated options to stop multicollinearity.
Instance:
In a gross sales prediction mannequin, if “advertising and marketing spend” and “advert finances” have a correlation > 0.9, preserving each might introduce redundancy. As a substitute, use one or create a derived function like “advertising and marketing effectivity = income/advert spend”.
5. Testing Options with Completely different Fashions to Consider Impression
Characteristic significance varies throughout totally different algorithms. A function that improves efficiency in a single mannequin may not be helpful in one other.
Finest Practices:
- Practice a number of fashions (Linear Regression, Resolution Timber, Neural Networks) and examine function significance.
- Use Permutation Significance or SHAP values to know every function’s contribution.
- Carry out Ablation Research (eradicating one function at a time) to measure efficiency affect.
Instance:
In a buyer churn mannequin:
- Resolution timber would possibly prioritize buyer complaints and contract sorts.
- Logistic regression would possibly discover tenure and month-to-month invoice quantities extra vital.
By testing totally different fashions, you’ll be able to determine probably the most useful options.
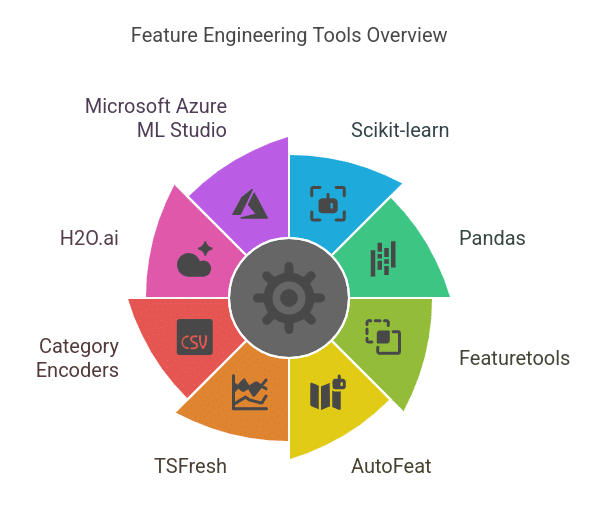
1. Python Libraries for Characteristic Engineering
Python is the go-to language for function engineering as a result of its strong libraries:
- Pandas – For knowledge manipulation, function extraction, and dealing with lacking values.
- NumPy – For mathematical operations and transformations on numerical knowledge.
- Scikit-learn – For preprocessing strategies like scaling, encoding, and have choice.
- Characteristic-engine – A specialised library with transformers for dealing with outliers, imputation, and categorical encoding.
- Scipy – Helpful for statistical transformations, like polynomial function technology and energy transformations.
Additionally Learn: Checklist of Python Libraries for Information Science and Evaluation
2. Automated Characteristic Engineering Instruments
- Featuretools – Automates the creation of latest options utilizing deep function synthesis (DFS).
- tsfresh – Extracts significant time-series options like development, seasonality, and entropy.
- AutoFeat – Automates function extraction and choice utilizing AI-driven strategies.
- H2O.ai AutoML – Performs computerized function transformation and choice.
3. Large Information Instruments for Characteristic Engineering
- Spark MLlib (Apache Spark) – Handles large-scale knowledge transformations and have extraction in distributed environments.
- Dask – Parallel processing for scaling function engineering on massive datasets.
- Feast (Characteristic Retailer by Tecton) – Manages and serves options effectively for machine studying fashions in manufacturing.
4. Characteristic Choice and Significance Instruments
- SHAP (Shapley Additive Explanations) – Measures function significance and affect on predictions.
- LIME (Native Interpretable Mannequin-agnostic Explanations) – Helps interpret particular person predictions and assess function relevance.
- Boruta – A wrapper methodology for choosing crucial options utilizing a random forest algorithm.
5. Visualization Instruments for Characteristic Engineering
- Matplotlib & Seaborn – For exploring function distributions, correlations, and traits.
- Plotly – For interactive function evaluation and sample detection.
- Yellowbrick – Gives visible diagnostics for function choice and mannequin efficiency.
Conclusion
Mastering function engineering is crucial for constructing high-performance machine studying fashions, and the precise instruments can considerably streamline the method.
Leveraging these instruments, from knowledge preprocessing with Pandas and Scikit-learn to automated function extraction with Featuretools and SHAP for interpretability, can improve mannequin accuracy and effectivity.
To realize hands-on experience in function engineering and machine studying, take this free function engineering course and elevate your profession as we speak!
Enroll in our MIT Information Science and Machine Studying Course to achieve full experience in such knowledge science and machine studying matters.
")